SQL Server 数据库索引其索引的小技巧
一、什么是索引 减少磁盘I/O和逻辑读次数的最佳方法之一就是使用【索引】 索引允许SQL Server在表中查找数据而不需要扫描整个表。 1.1、索引的好处: 当表没有聚集索引时,成为【堆或堆表】 【堆】是一堆未加工的数据,以行标识符作为指向存储位置的指针。表数据没有顺序,也不能搜索,除非逐行遍历。
一、什么是索引 减少磁盘I/O和逻辑读次数的最佳方法之一就是使用【索引】 索引允许SQL Server在表中查找数据而不需要扫描整个表。 1.1、索引的好处: 当表没有聚集索引时,成为【堆或堆表】 【堆】是一堆未加工的数据,以行标识符作为指向存储位置的指针。表数据没有顺序,也不能搜索,除非逐行遍历。
进入 安装目录.../bin/mysql.exe cd 更换目录 dir列出当前目录所有文件 c:\vesa\...\a> 尖括号表示在c盘/的vasa/的.../的a 文件夹里面 cd空格.. 表示向上一级目录 cd空格目录名 表示进入指定目录 cd空格ted健 表示顺序查看目录名 >
A.内部排序(直接加载到内存进行排序):包括交换式排序(冒泡和快速法)、选择式排序、插入式排序 B.外部排序(因数据量大,需借助外部存储进行排序):包括合并排序、直接合并排序 【冒泡排序:从后向前,依次比较相邻元素的排序码,若发现逆序则交换,一轮结束后,再来一轮,直到所有相邻数无逆序,即按顺序排完】
1. 合并数组 array_merge()函数将数组合并到一起,返回一个联合的数组。所得到的数组以第一个输入数组参数开始,按后面数组参数出现的顺序依次迫加。其形式为: 实现代码如下: array array_merge (array array1 array2…,arrayN)这个函数将一个或多个数
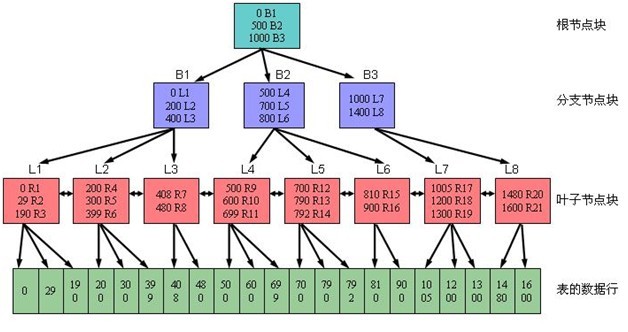
聚集索引,数据实际上是按顺序存储的,数据页就在索引页上。就好像参考手册将所有主题按顺序编排一样。一旦找到了所要搜索的数据,就完成了这次搜索,对于非聚集索引,索引是安全独立于数据本身结构的,在索引中找到了寻找的数据,然后通过指针定位到实际的数据。SQL Server中的索引使用标准的B-树来存储他们的
尽管 ORDER BY 不是和索引的顺序准确匹配,索引还是可以被用到,只要不用的索引部分和所有的额外的 ORDER BY 字段在 WHERE 子句中都被包括了。 使用索引的MySQL Order By 下列的几个查询都会使用索引来解决 ORDER BY 或 GROUP BY 部分: 实现代码如下:
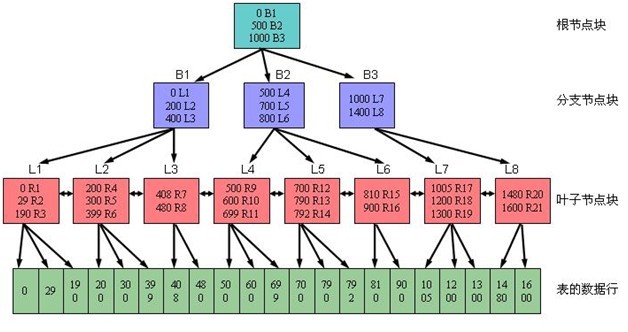
聚集索引,数据实际上是按顺序存储的,数据页就在索引页上。就好像参考手册将所有主题按顺序编排一样。一旦找到了所要搜索的数据,就完成了这次搜索,对于非聚集索引,索引是安全独立于数据本身结构的,在索引中找到了寻找的数据,然后通过指针定位到实际的数据。 SQL Server中的索引使用标准的B-树来存储他们
一,for循环的基本写法 代码如下: 实现代码如下: //例一for(var i=1;i0;i--){ //alert(i); }为什么倒序会比顺序效率快?没有科学道理啊!其实只是因为倒序可以少用一个变量(对比下上一个例子吧),除开这点,两者没有速度差别。 3,注意跳出 不进行不必要的操作,这是基本
用到的函数: str_split:把字符串分割到数组中。类似的函数explode() 函数把字符串分割为数组。array_count_values:用于统计数组中所有值出现的次数。arsort:对数组进行逆向排序并保持索引关系。主要用于对那些单元顺序很重要的结合数组进行排序。$str="asdfgf
一、先说一下Shell脚本语言自身的局限性 作为解释型的脚本语言,天生就有效率上边的缺陷。尽管它调用的其他命令可能效率上是不错的。 Shell脚本程序的执行是顺序执行,而非并行执行的。这很大程度上浪费了可能能利用上的系统资源。 Shell每执行一个命令就创建一个新的进程,如果脚本编写者没有这方面意识