浏览器加载、渲染和解析过程黑箱简析
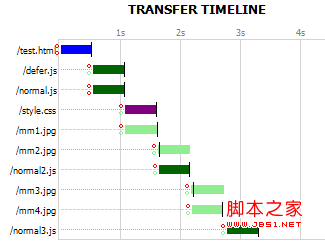
用 Fiddler 监控,在 IE6 下,资源下载顺序为:很明显,下载顺序从上到下,文档流中先出现的资源先下载。在 IE8, Safari, Chrome 等浏览器下也类似。Firefox 对下载顺序做了优化:Firefox 会将 js, css 提前下载,而将图片等资源延迟到后面下载。对于渲染,利
用 Fiddler 监控,在 IE6 下,资源下载顺序为:很明显,下载顺序从上到下,文档流中先出现的资源先下载。在 IE8, Safari, Chrome 等浏览器下也类似。Firefox 对下载顺序做了优化:Firefox 会将 js, css 提前下载,而将图片等资源延迟到后面下载。对于渲染,利
本人工作有一个月多了。对于android很多东西,都有了新的了解或者说真正的掌握。为了让更多的像我这样的小白少走弯路,所以我会坚持将我在工作中遇到的一些比较令我印象深刻的知识点整合出来给大家(顺序是按照我工作到现在的时间来制作的,其实也是想给自己一个记录吧。记录自己一路走来以及以后的路, 至少我想找
一个全局的变量var JsonData; 我这里有一个Ajax处理的方法: JScript code: 实现代码如下: function GetJson(DataSourceName) { $.ajax({ type: “post”, url: “Ajax/AjaxData.ashx?MethodN
首先我们先来了解一下ASP页面执行的流程 1.IIS找到ASP文件,提交给ASP引擎(一般是ASP.DLL)处理。 2.引擎打开这个ASP文件,找出之间的内容,当然还有和对应的之间的内容,这些内容称为脚本块。只有脚本块里的内容被引擎解析,其他内容不管,作为没有意义的字符插在脚本块之间。有必要说明一下
首先介绍一下什么是Map。在数组中我们是通过数组下标来对其内容索引的,而在Map中我们通过对象来对对象进行索引,用来索引的对象叫做key,其对应的对象叫做value。这就是我们平时说的键值对。HashMap通过hashcode对其内容进行快速查找,而 TreeMap中所有的元素都保持着某种固定的顺序
新增的APPLY表运算符把右表表达式应用到左表表达式中的每一行。它不像JOIN那样先计算那个表表达式都可以,APPLY必选先逻辑地计算左表达式。这种计算输入的逻辑顺序允许吧右表达式关联到左表表达式。 APPLY有两种形式,一个是OUTER APPLY,一个是CROSS APPLY,区别在于指定OUT
在SQL Server中联机丛书是这样说的: SQL Server timestamp 数据类型与时间和日期无关。SQL Server timestamp 是二进制数字,它表明数据库中数据修改发生的相对顺序。实现 timestamp 数据类型最初是为了支持 SQL Server 恢复算法。每次修改页
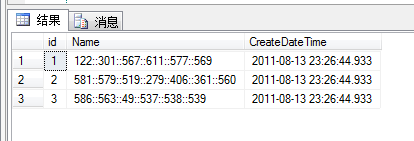
概述 -------------------------------------------------------------------------------- 在平时的工作中,我会经常的碰到这样需要合并SQL脚本的问题。如,有很多的SQL脚本文件,需要按照一定的先后顺序,再生成一个合并SQL

这里只讨论支持并行下载的浏览情况,大致分为两种,一种是按加向DOM树中加的顺序执行,另一种按下载完成的先后顺序执行;这样如果js文件间有依赖关系的话,且是按下载顺序执行,且在没有缓存的情况下就会报错(通常的情况下第一次执行会报错,http返回状态200,如果缓存未禁用,http状态是304,就不会报
注意: JavaScript 中数组不是 关联数组。 JavaScript 中只有对象 来管理键值的对应关系。但是关联数组是保持顺序的,而对象不是。 由于 for in 循环会枚举原型链上的所有属性,唯一过滤这些属性的方式是使用 `hasOwnProperty` 函数,因此会比普通的 for 循环慢