
Python+Redis实现布隆过滤器
布隆过滤器是什么布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。布隆过滤器的基本思想通过一种叫作散
布隆过滤器是什么布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。布隆过滤器的基本思想通过一种叫作散
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。本文将介绍布隆过滤器的原理以及Redis如何实现布
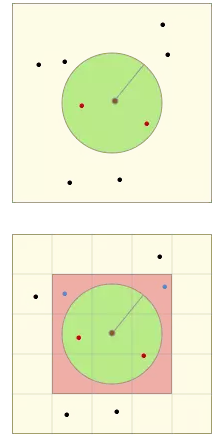
针对“附近的人”这一位置服务领域的应用场景,常见的可使用PG、MySQL和MongoDB等多种DB的空间索引进行实现。而Redis另辟蹊径,结合其有序队列zset以及geohash编码,实现了空间搜索功能,且拥有极高的运行效率。本文将从源码角度对其算法原理进行解析,并推算查询时间复杂度。操作命令自R

当往MongoDB中插入一条数据时,会自动生成ObjectId作为数据的主键。 那么如何通过ObjectId来做数据的唯一查询呢?在MongoDB中插入一条数据在MongoDB中插入一条如下结构的数据:{_id: 5d6a32389c825e24106624e4,title: 'GitHub 上有什
前言模糊查询是数据库的基本操作之一,实现对给定的字符串是否与指定的模式进行匹配。如果字符完全匹配,可以用=等号表示,如果部分匹配可认为是一种模糊查询。在关系型数据中,通过SQL使用like ‘%fens%'的语法。那么在mongodb中我们应该如何实现模糊查询的效果呢。查询条件关键字说明$or或关系
MongoDB按照天数或小时聚合需求最近接到需求,需要对用户账户下的设备状态,分别按照天以及小时进行聚合,以此为基础绘制设备状态趋势图.实现思路是启动定时任务,对各用户的设备状态数据分别按照小时以及天进行聚合,并存储进数据库中供用户后续查询.涉及到的技术栈分别为:Spring Boot,MongoD
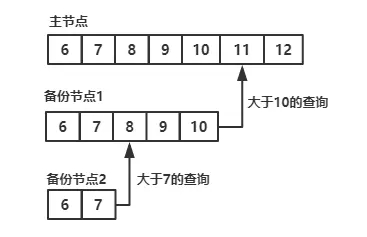
前言任何一种数据库都有各种各样的日志,MongoDB也不例外。MongoDB中有4种日志,分别是系统日志、Journal日志、oplog主从日志、慢查询日志等。这些日志记录着MongoDB数据库不同方面的踪迹。下面分别介绍这几种日志。系统日志系统日志在MongoDB数据库中很重要,它记录着Mongo
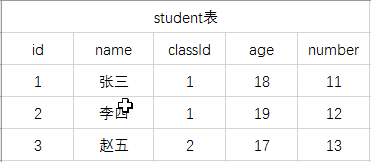
本文实例讲述了MongoDB多表关联查询操作。分享给大家供大家参考,具体如下:Mongoose的多表关联查询首先,我们回忆一下,MySQL多表关联查询的语句:student表:calss表:通过student的classId关联进行查询学生名称,班级的数据:SELECT student.name,s
1.作用与语法描述作用: 正则表达式是使用指定字符串来描述、匹配一系列符合某个句法规则的字符串。许多程序设计语言都支持利用正则表达式进行字符串操作。MongoDB 使用 $regex 操作符来设置匹配字符串的正则表达式。语法一{ : { $regex: /pattern/, $options: ''

写在前面React在16.8版本正式发布了Hooks。关注了很久,最近正好有一个小需求,赶紧来试一下。需求描述需求很简单,部门内部的一个数据查询小工具。大致长成下面这样:用户首次访问页面,会拉取数据展示。输入筛选条件,点击查询后,会再次拉取数据在前端展示。需求实现使用React Class Comp