在SQL Server中使用SQL语句查询一个存储过程被其它所有的存储过程引用的存储过程名
这个问题对于规模稍微大些的项目而言,显得尤其重要了,数据库中如果有几百个存储过程, 难道还一个个找不成,即使自己很了解业务和系统,时间长了,也难免能记得住。 如何使用SQL语句进行查询呢? 下面就和大家分享下SQL查询的方法: 实现代码如下:select distinct name from sys
这个问题对于规模稍微大些的项目而言,显得尤其重要了,数据库中如果有几百个存储过程, 难道还一个个找不成,即使自己很了解业务和系统,时间长了,也难免能记得住。 如何使用SQL语句进行查询呢? 下面就和大家分享下SQL查询的方法: 实现代码如下:select distinct name from sys
将ubk_vhost_list表中的字段userid中的字符10005替换成10010 UPDATE `table_name` SET `field_name` = replace (`field_name`,'from_str','to_str') WHERE `field_name` LIKE
实现代码如下: SELECT * FROM (SELECT TRUNC(SYSDATE, 'mm') + ROWNUM - 1 DAYS FROM (SELECT LEVEL FROM DUAL CONNECT BY LEVEL <= TRUNC(LAST_DAY(SYSDATE)) - TR
Union 与 Union ALL 的作用都是合并 SELECT 的查询结果集,那么它们有什么不同呢? Union 将查询到的结果集合并后进行重查,将其中相同的行去除。缺点:效率低; 而Union ALL 则只是合并查询的结果集,并不重新查询,效率高,但是可能会出现冗余数据。 我们举个例子来说明一下
(一)行号显示和排序 1.SQL Server的行号 A.SQL 2000使用identity(int,1,1)和临时表,可以显示行号 SELECT identity(int,1,1) AS ROWNUM, [DataID] INTO #1 FROM DATAS order by DataID; S
1. TVP, 表变量,临时表,CTE 的区别 TVP和临时表都是可以索引的,总是存在tempdb中,会增加系统数据库开销,而表变量和CTE只有在内存溢出时才会被写入tempdb中。对于数据量大,并且反复使用,反复进行查询关联的,建议使用临时表或TVP,数据量小,使用表变量或CTE比较合适 2. s
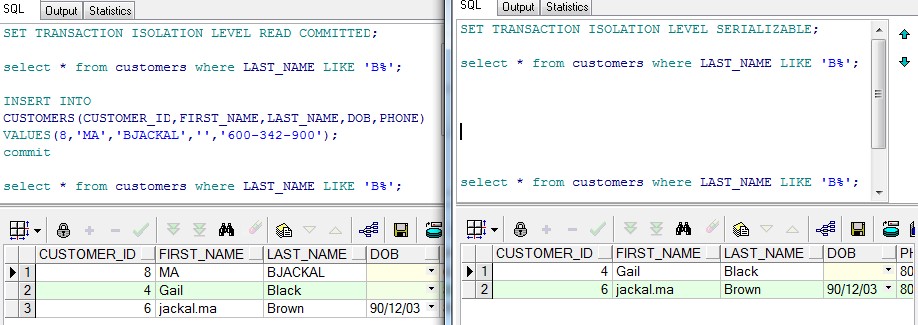
两个并发事务同时访问数据库表相同的行时,可能存在以下三个问题:1、幻想读:事务T1读取一条指定where条件的语句,返回结果集。此时事务T2插入一行新记录,恰好满足T1的where条件。然后T1使用相同的条件再次查询,结果集中可以看到T2插入的记录,这条新纪录就是幻想。2、不可重复读取:事务T1读取
创建用户定义函数,它是返回值的已保存的 Transact-SQL 例程。用户定义函数不能用于执行一组修改全局数据库状态的操作。与系统函数一样,用户定义函数可以从查询中唤醒调用。也可以像存储过程一样,通过 EXECUTE 语句执行。 用户定义函数用 ALTER FUNCTION 修改,用 DROP F
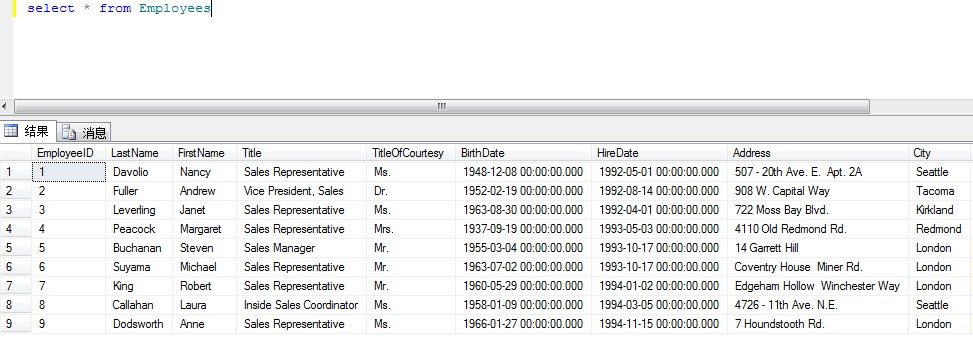
使用Northwind 数据库首先查询Employees表查询结果:city列里面只有5个城市使用ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2) 先进行分组 注:根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后
今天在使用ORDER BY的过程中出现了一点问题,发现之前对ORDER BY理解是错误的。 之前在w3s网站上看到ORDER BY的用法,以为是对选出来的数据按关键字升序或者降序排列,结果今天尝试select数据集数据的时候,发现使用ORDER BY 和ORDER BY DESC得出的查询结果完全不