
js require 查找模块的顺序
require 查找模块的顺序在 Node 中模块有两类:核心模块和文件模块。在 Node 中引入模块需要三个步骤:路径分析文件定位编译执行Node 也是采用缓存优先策略,对加载过的模块都会进行缓存,以减少二次引入的开销。当然,核心模块的加载是优于文件模块加载的。require()接受一个标识符作为
require 查找模块的顺序在 Node 中模块有两类:核心模块和文件模块。在 Node 中引入模块需要三个步骤:路径分析文件定位编译执行Node 也是采用缓存优先策略,对加载过的模块都会进行缓存,以减少二次引入的开销。当然,核心模块的加载是优于文件模块加载的。require()接受一个标识符作为

楔子我们知道python的执行效率不是很高,而且由于GIL的原因,导致python不能充分利用多核CPU。一般的解决方式是使用多进程,但是多进程开销比较大,而且进程之间的通信也会比较麻烦。因此在解决效率问题上,我们会把那些比较耗时的模块使用C或者C++编写,然后编译成动态链接库,Windows上面是
1、数据库访问性能优化 A、尽量减少数据库连接,并充分利用每次数据库连接:连接的创建、打开和关闭是有开销的。可以使用连接池 B、合理使用存储过程:存储过程是存储在服务器端的一组预编译的SQL。使用存储过程可以避免对SQL的多次编译,后续查询可以复用之前的执行计划。另外存储过程可以减少SQL语句网络传
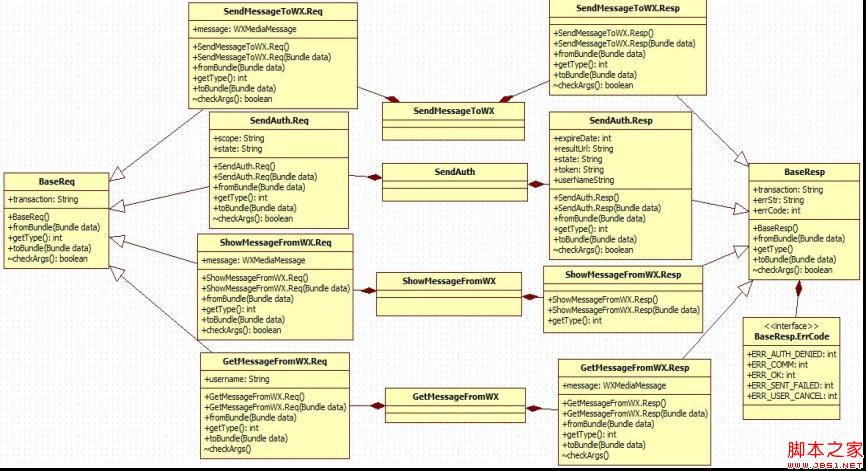
微信平台开放后倒是挺火的,许多第三方应用都想试下接入微信这个平台,毕竟可以利用微信建立起来的关系链来拓展自己的应用还是挺不错的,可以节约很多在社交方面的开销,我最近由于实习需要也在研究这个东西,不过发现网上的相关资料还是挺少的,这里把我的整个研究情况给出来,希望可以共同学习。一、微信SDK中会用到主
1. TVP, 表变量,临时表,CTE 的区别 TVP和临时表都是可以索引的,总是存在tempdb中,会增加系统数据库开销,而表变量和CTE只有在内存溢出时才会被写入tempdb中。对于数据量大,并且反复使用,反复进行查询关联的,建议使用临时表或TVP,数据量小,使用表变量或CTE比较合适 2. s
1. TVP, 表变量,临时表,CTE 的区别 TVP和临时表都是可以索引的,总是存在tempdb中,会增加系统数据库开销,而表变量和CTE只有在内存溢出时才会被写入tempdb中。对于数据量大,并且反复使用,反复进行查询关联的,建议使用临时表或TVP,数据量小,使用表变量或CTE比较合适 2. s

请看如下代码: 实现代码如下: var arr = []; var cc = function(){alert('xx');}; for(var i = 0; i<2; i++){ arr[i] = function(){alert('yy');} arr[i+10] = cc; } cons
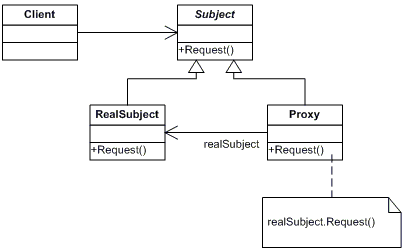
代理模式的应用:远程代理,为一个对象在不同的地址空间提供局部代表,可以隐藏一个对象存在于不同地质空间的事实。虚拟代理,根据需要创建开销很大的对象,通过代理来存放实例化需要很长时间的真实对象。安全代理,用来控制真实对象的访问权限。智能代理,当调用代理时,可以代理处理一些额外的功能。案例场景: 向一位自
mysqli对prepare的支持对于大访问量的网站是很有好处的,它极大地降低了系统开销,而且保证了创建查询的稳定性和安全性。prepare准备语句分为绑定参数和绑定结果,下面将会一一介绍! (1)绑定参数 看下面php代码: 实现代码如下: prepare("insert into `vol_ms
在网站的开发过程中,经常碰到的一类需求场景是: 1:页面含热点新闻,热点新闻部分需要10分钟更新一次,而整个页面的其它部分1天内都不会变动; 2:首页的某个BANNER需要显式:欢迎***; 上面场景中的1,如果整个页面的缓存失效都定为10分钟,则势必增加性能开销,所以最好的策略是页面的不同部分采用