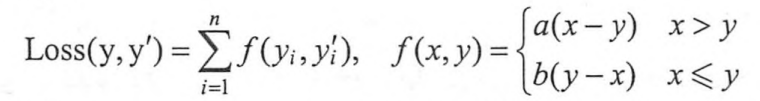
TensorFlow自定义损失函数来预测商品销售量
在预测商品销量时,如果预测多了(预测值比真实销量大),商家损失的是生产商品的成本;而如果预测少了(预测值比真实销量小),损失的则是商品的利润。因为一般商品的成本和商品的利润不会严格相等,比如如果一个商品的成本是1元,但是利润是10元,那么少预测一个就少挣10元;而多预测一个才少挣1元,所以如果神经网
在预测商品销量时,如果预测多了(预测值比真实销量大),商家损失的是生产商品的成本;而如果预测少了(预测值比真实销量小),损失的则是商品的利润。因为一般商品的成本和商品的利润不会严格相等,比如如果一个商品的成本是1元,但是利润是10元,那么少预测一个就少挣10元;而多预测一个才少挣1元,所以如果神经网
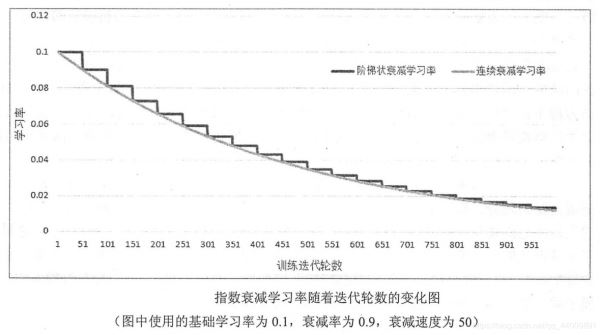
在TensorFlow中,tf.train.exponential_decay函数实现了指数衰减学习率,通过这个函数,可以先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率,使得模型在训练后期更加稳定。tf.train.exponential_decay(learning_

当我们在大型的数据集上面进行深度学习的训练时,往往需要大量的运行资源,而且还要花费大量时间才能完成训练。1.分布式TensorFlow的角色与原理在分布式的TensorFlow中的角色分配如下:PS:作为分布式训练的服务端,等待各个终端(supervisors)来连接。worker:在TensorF
MNIST数据集介绍MNIST数据集中包含了各种各样的手写数字图片,数据集的官网是:http://yann.lecun.com/exdb/mnist/index.html,我们可以从这里下载数据集。使用如下的代码对数据集进行加载:from tensorflow.examples.tutorials.
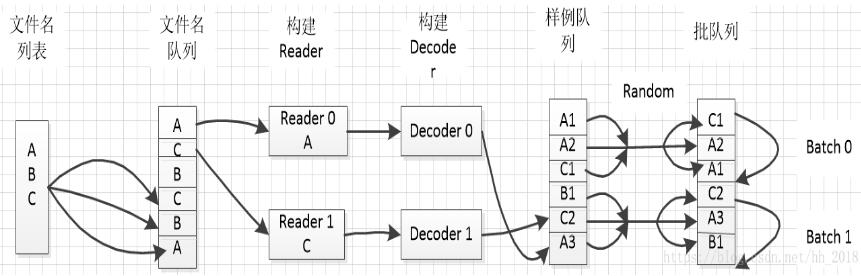
最近研究了一下并行读入数据的方式,现在将自己的理解整理如下,理解比较浅,仅供参考。并行读入数据主要分1. 创建文件名列表2. 创建文件名队列3. 创建Reader和Decoder4. 创建样例列表5. 创建批列表(读取时可要可不要,一般情况下样例列表可以执行读取数据操作,但是在实际训练的时候往往需要
关于 TensorFlowTensorFlow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台
这个自定义损失函数的背景:(一般回归用的损失函数是MSE, 但要看实际遇到的情况而有所改变)我们现在想要做一个回归,来预估某个商品的销量,现在我们知道,一件商品的成本是1元,售价是10元。如果我们用均方差来算的话,如果预估多一个,则损失一块钱,预估少一个,则损失9元钱(少赚的)。显然,我宁愿预估多了
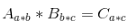
Tensorflow二维、三维、四维矩阵运算(矩阵相乘,点乘,行/列累加)1. 矩阵相乘 根据矩阵相乘的匹配原则,左乘矩阵的列数要等于右乘矩阵的行数。在多维(三维、四维)矩阵的相乘中,需要最后两维满足匹配原则。可以将多维矩阵理解成:(矩阵排列,矩阵),即后两维为矩阵,前面的维度为矩阵的排列。比如对于
由于python内部的变量其实都是reference,而Tensorflow实现的时候也没有意义去判断输出是否是同一变量名,从而判定是否要新建一个Tensor用于输出。Tensorflow为了满足所有需求,定义了两个不同的函数:tf.add和tf.assign_add。从名字即可看出区别,累加应该使
TensorFlow从txt文件中读取数据的方法很多有种,我比较常用的是下面两种:【1】np.loadtxtimport numpy as npdata=np.loadtxt('ex1data1.txt',dtype='float',delimiter=',')X_train=data[:,0]y_