在项目中遇到需要处理超级大量的数据集,无法载入内存的问题就不用说了,单线程分批读取和处理(虽然这个处理也只是特别简单的首尾相连的操作)也会使瓶颈出现在CPU性能上,所以研究了一下多线程和多进程的数据读取和预处理,都是通过调用dataset api实现
1. 多线程数据读取
第一种方法是可以直接从csv里读取数据,但返回值是tensor,需要在sess里run一下才能返回真实值,无法实现真正的并行处理,但如果直接用csv文件或其他什么文件存了特征值,可以直接读取后进行训练,可使用这种方法.
import tensorflow as tf
#这里是返回的数据类型,具体内容无所谓,类型对应就好了,比如我这个,就是一个四维的向量,前三维是字符串类型 最后一维是int类型
record_defaults = [[""], [""], [""], [0]]
def decode_csv(line):
parsed_line = tf.decode_csv(line, record_defaults)
label = parsed_line[-1] # label
del parsed_line[-1] # delete the last element from the list
features = tf.stack(parsed_line) # Stack features so that you can later vectorize forward prop., etc.
#label = tf.stack(label) #NOT needed. Only if more than 1 column makes the label...
batch_to_return = features, label
return batch_to_return
filenames = tf.placeholder(tf.string, shape=[None])
dataset5 = tf.data.Dataset.from_tensor_slices(filenames)
#在这里设置线程数目
dataset5 = dataset5.flat_map(lambda filename: tf.data.TextLineDataset(filename).skip(1).map(decode_csv,num_parallel_calls=15))
dataset5 = dataset5.shuffle(buffer_size=1000)
dataset5 = dataset5.batch(32) #batch_size
iterator5 = dataset5.make_initializable_iterator()
next_element5 = iterator5.get_next()
#这里是需要加载的文件名
training_filenames = ["train.csv"]
validation_filenames = ["vali.csv"]
with tf.Session() as sess:
for _ in range(2):
#通过文件名初始化迭代器
sess.run(iterator5.initializer, feed_dict={filenames: training_filenames})
while True:
try:
#这里获得真实值
features, labels = sess.run(next_element5)
# Train...
# print("(train) features: ")
# print(features)
# print("(train) labels: ")
# print(labels)
except tf.errors.OutOfRangeError:
print("Out of range error triggered (looped through training set 1 time)")
break
# Validate (cost, accuracy) on train set
print("\nDone with the first iterator\n")
sess.run(iterator5.initializer, feed_dict={filenames: validation_filenames})
while True:
try:
features, labels = sess.run(next_element5)
# Validate (cost, accuracy) on dev set
# print("(dev) features: ")
# print(features)
# print("(dev) labels: ")
# print(labels)
except tf.errors.OutOfRangeError:
print("Out of range error triggered (looped through dev set 1 time only)")
break
第二种方法,基于生成器,可以进行预处理操作了,sess里run出来的结果可以直接进行输入训练,但需要自己写一个生成器,我使用的测试代码如下:
import tensorflow as tf
import random
import threading
import numpy as np
from data import load_image,load_wave
class SequenceData():
def __init__(self, path, batch_size=32):
self.path = path
self.batch_size = batch_size
f = open(path)
self.datas = f.readlines()
self.L = len(self.datas)
self.index = random.sample(range(self.L), self.L)
def __len__(self):
return self.L - self.batch_size
def __getitem__(self, idx):
batch_indexs = self.index[idx:(idx+self.batch_size)]
batch_datas = [self.datas[k] for k in batch_indexs]
img1s,img2s,audios,labels = self.data_generation(batch_datas)
return img1s,img2s,audios,labels
def gen(self):
for i in range(100000):
t = self.__getitem__(i)
yield t
def data_generation(self, batch_datas):
#预处理操作,数据在参数里
return img1s,img2s,audios,labels
#这里的type要和实际返回的数据类型对应,如果在自己的处理代码里已经考虑的batchszie,那这里的batch设为1即可
dataset = tf.data.Dataset().batch(1).from_generator(SequenceData('train.csv').gen,
output_types= (tf.float32,tf.float32,tf.float32,tf.int64))
dataset = dataset.map(lambda x,y,z,w : (x,y,z,w), num_parallel_calls=32).prefetch(buffer_size=1000)
X, y,z,w = dataset.make_one_shot_iterator().get_next()
with tf.Session() as sess:
for _ in range(100000):
a,b,c,d = sess.run([X,y,z,w])
print(a.shape)
不过python的多线程并不是真正的多线程,虽然看起来我是启动了32线程,但运行时的CPU占用如下所示:
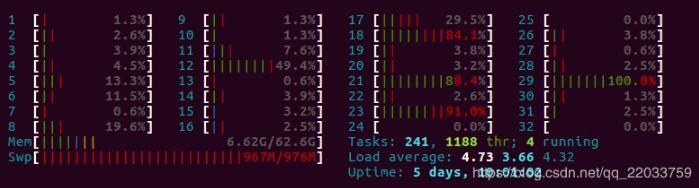
还剩这么多核心空着,然后就是第三个版本了,使用了queue来缓存数据,训练需要数据时直接从queue中进行读取,是一个到多进程的过度版本(vscode没法debug多进程,坑啊,还以为代码写错了,在vscode里多进程直接就没法运行),在初始化时启动多个线程进行数据的预处理:
import tensorflow as tf
import random
import threading
import numpy as np
from data import load_image,load_wave
from queue import Queue
class SequenceData():
def __init__(self, path, batch_size=32):
self.path = path
self.batch_size = batch_size
f = open(path)
self.datas = f.readlines()
self.L = len(self.datas)
self.index = random.sample(range(self.L), self.L)
self.queue = Queue(maxsize=20)
for i in range(32):
threading.Thread(target=self.f).start()
def __len__(self):
return self.L - self.batch_size
def __getitem__(self, idx):
batch_indexs = self.index[idx:(idx+self.batch_size)]
batch_datas = [self.datas[k] for k in batch_indexs]
img1s,img2s,audios,labels = self.data_generation(batch_datas)
return img1s,img2s,audios,labels
def f(self):
for i in range(int(self.__len__()/self.batch_size)):
t = self.__getitem__(i)
self.queue.put(t)
def gen(self):
while 1:
yield self.queue.get()
def data_generation(self, batch_datas):
#数据预处理操作
return img1s,img2s,audios,labels
#这里的type要和实际返回的数据类型对应,如果在自己的处理代码里已经考虑的batchszie,那这里的batch设为1即可
dataset = tf.data.Dataset().batch(1).from_generator(SequenceData('train.csv').gen,
output_types= (tf.float32,tf.float32,tf.float32,tf.int64))
dataset = dataset.map(lambda x,y,z,w : (x,y,z,w), num_parallel_calls=1).prefetch(buffer_size=1000)
X, y,z,w = dataset.make_one_shot_iterator().get_next()
with tf.Session() as sess:
for _ in range(100000):
a,b,c,d = sess.run([X,y,z,w])
print(a.shape)
2. 多进程数据读取
这里的代码和多线程的第三个版本非常类似,修改为启动进程和进程类里的Queue即可,但千万不要在vscode里直接debug!在vscode里直接f5运行进程并不能启动.
from __future__ import unicode_literals
from functools import reduce
import tensorflow as tf
import numpy as np
import warnings
import argparse
import skimage.io
import skimage.transform
import skimage
import scipy.io.wavfile
from multiprocessing import Process,Queue
class SequenceData():
def __init__(self, path, batch_size=32):
self.path = path
self.batch_size = batch_size
f = open(path)
self.datas = f.readlines()
self.L = len(self.datas)
self.index = random.sample(range(self.L), self.L)
self.queue = Queue(maxsize=30)
self.Process_num=32
for i in range(self.Process_num):
print(i,'start')
ii = int(self.__len__()/self.Process_num)
t = Process(target=self.f,args=(i*ii,(i+1)*ii))
t.start()
def __len__(self):
return self.L - self.batch_size
def __getitem__(self, idx):
batch_indexs = self.index[idx:(idx+self.batch_size)]
batch_datas = [self.datas[k] for k in batch_indexs]
img1s,img2s,audios,labels = self.data_generation(batch_datas)
return img1s,img2s,audios,labels
def f(self,i_l,i_h):
for i in range(i_l,i_h):
t = self.__getitem__(i)
self.queue.put(t)
def gen(self):
while 1:
t = self.queue.get()
yield t[0],t[1],t[2],t[3]
def data_generation(self, batch_datas):
#数据预处理操作
return img1s,img2s,audios,labels
epochs = 2
data_g = SequenceData('train_1.csv',batch_size=48)
dataset = tf.data.Dataset().batch(1).from_generator(data_g.gen,
output_types= (tf.float32,tf.float32,tf.float32,tf.float32))
X, y,z,w = dataset.make_one_shot_iterator().get_next()
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(epochs):
for j in range(int(len(data_g)/(data_g.batch_size))):
face1,face2,voice, labels = sess.run([X,y,z,w])
print(face1.shape)
然后,最后实现的效果

以上这篇Tensorflow 多线程与多进程数据加载实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
以上就是【Tensorflow 多线程与多进程数据加载实例】的全部内容了,欢迎留言评论进行交流!