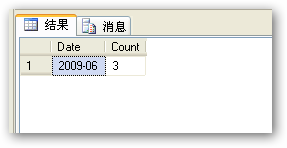
SQLserver 实现分组统计查询(按月、小时分组)
设置AccessCount字段可以根据需求在特定的时间范围内如果是相同IP访问就在AccessCount上累加。 实现代码如下:Create table Counter ( CounterID int identity(1,1) not null, IP varchar(20), AccessDat
设置AccessCount字段可以根据需求在特定的时间范围内如果是相同IP访问就在AccessCount上累加。 实现代码如下:Create table Counter ( CounterID int identity(1,1) not null, IP varchar(20), AccessDat

对于 SQL SERVER 2000 及更早的版本,需要使用一个自增列,结合临时表来实现。 实现代码如下:SELECT [AUTOID] = IDENTITY(int,1,1), * INTO #temp_table FROM 表名; 实现代码如下:SELECT * FROM #temp_table
实现代码如下:-- Create a log table CREATE TABLE TriggerLog (LogInfo xml) -- Create a dummy table to delete later on CREATE TABLE TableToDelete (Id int PRIMA
--创建测试数据库 CREATE DATABASE Db GO --对数据库进行备份 BACKUP DATABASE Db TO DISK='c:\db.bak' WITH FORMAT GO --创建测试表 CREATE TABLE Db.dbo.TB_test(ID int) --延时1秒钟,再
下面介绍一下把Output同2008的新T-SQL语句Merge组合使用的方法: 新建下面表:实现代码如下:CREATE TABLE Book( ISBN varchar(20) PRIMARY KEY, Price decimal, Shelf int) CREATE TABLE WeeklyCh
如果你的硬盘空间小,并且不想设置数据库的日志为最小(因为希望其他正常的日志希望仍然记录),而且对速度要求比较高,并清除所有的数据建议你用turncate table1,因为truncate 是DDL操作,不产生rollback,不写日志速度快一些,然后如果有自增的话,恢复到1开始,而delete会产
下面方法可以用来快速生成一批数据 if(object_id('t') is not null) drop table t go create table t(id int identity(1,1),name varchar(40)) go insert into t(name) select ne
运行下面的脚本,建立测试数据库和表值参数。 实现代码如下:--Create DataBase create database BulkTestDB; go use BulkTestDB; go --Create Table Create table BulkTestTable( Id int pri
代码如下:本文相关代码如下:Access:select top n * from table order by rnd(id)'id为数据库的自动编号字段Sql Server:select top n * from table order by newid()但在ASP+Access中,或许是因为缓
语法很简单,比如 实现代码如下:declare @t table (id uniqueidentifier default newid (), name varchar (100 )) insert into @t (name ) output inserted .id select 'jinjaz