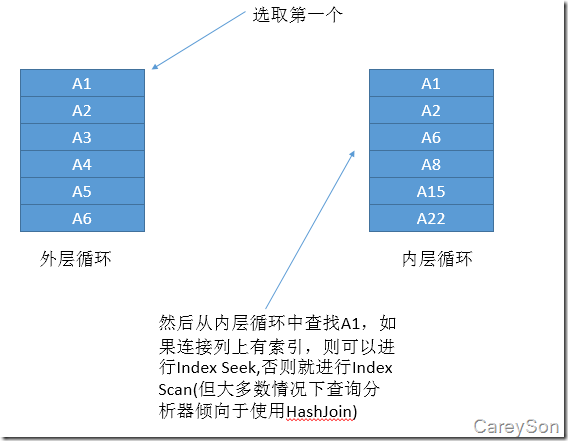
浅谈SQL Server中的三种物理连接操作(性能比较)
在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge Join,Hash Join这三种物理连接中的一种。理解这三种物理连接是理解在表连接时解决性能问题的基础,下
在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge Join,Hash Join这三种物理连接中的一种。理解这三种物理连接是理解在表连接时解决性能问题的基础,下
本系列文章是我在sqlskill.com的PAUL的博客看到的,很多误区都比较具有典型性和代表性,原文来自T-SQL Tuesday #11: Misconceptions about.... EVERYTHING!!,经过我们团队的翻译和整理发布在AgileSharp和博客园上。希望对大家有所帮助
误区 #29:可以通过对堆建聚集索引再DROP后进行堆上的碎片整理Nooooooooooooo!!!对堆建聚集索引再DROP在我看来是除了收缩数据库之外最2的事了。如果你通过sys.dm_db_index_physical_stats(或是老版本的DBCC SHOWCONTIG)看到堆上有碎片,绝对
将数组arr2插入到数组arr1的index位置: 实现代码如下: var arr1 = ['a', 'b', 'c']; var arr2 = ['1', '2', '3']; var index = 1; arr2.unshift(index, 0);Array.prototype.splice
实现代码如下:var gaJsHost = (("https:" == document.location.protocol) ? "https://ssl." : "http://www."); $.getScript(gaJsHost + "google-analytics.com/ga.js"
先说一下自己的一点小心得: 可能很多在高版本下编绎apk的同学,可能都曾有和我一样的困惑,就是如何让低版本的用户也能有高版本的体验呢,比如3.0才能用的holo style. 于是很多人为此求助了很多开源的sdk,比如holo everywhere,sherlockactionbar等等,但是这些库
1 利用pgrep 匹配名字 实现代码如下: if test $( pgrep -f $1 | wc -l ) -eq 0 then echo "进程不存在" else echo "存在进程" fi以下是补充内容: 当前系统中的进程: apple@ubuntu:~$ ps -ef UID PID P
实现代码如下: #!/bin/sh export BACK_DATE=`date +%Y%m%d` export BACKUP_PATH=/home/oracle/dbbak echo `mkdir -p ${BACKUP_PATH}/archivelog/${BACK_DATE}` rman ms
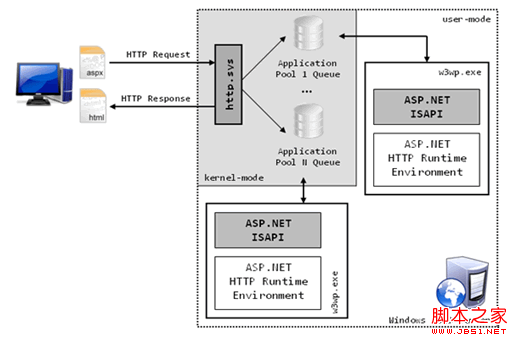
最近看了几篇讲述httpHandler和HttpModuler的文章,总的来说还是Fish li的那篇文章给力,但是他是大牛,他写出来的文章技术含量太高,对于像我这样的小兵,要完全看懂估计需要看几遍。虽然说没有完全了解底层操作,但是我也算明白了一个请求从进入IIS到最后输出都经历了哪些过程。说实话,
特殊文件夹名称用于索引该集合以检索所需的特殊文件夹,文档中列出了下面的特殊文件夹: AllUsersDesktop AllUsersStartMenu AllUsersPrograms AllUsersStartup Desktop Favorites Fonts MyDocuments NetHo