hadoop 单机安装配置教程
单机安装主要用于程序逻辑调试。安装步骤基本通分布式安装,包括环境变量,主要Hadoop配置文件,SSH配置等。主要的区别在于配置文件:slaves配置需要修改,另外如果分布式安装中dfs.replication大于1,需要修改为1,因为只有1个datanode. 分布式安装请参考: http://a
单机安装主要用于程序逻辑调试。安装步骤基本通分布式安装,包括环境变量,主要Hadoop配置文件,SSH配置等。主要的区别在于配置文件:slaves配置需要修改,另外如果分布式安装中dfs.replication大于1,需要修改为1,因为只有1个datanode. 分布式安装请参考: http://a
代码如下:我写了个方法,用于查询结果,但debug过程中发现结果集有数据,我如何通过变量获取呢? JScript code 实现代码如下: function getChildNodeArrayByParentID(categoryCode) { $.ajax( { type: "get", url:
实现代码如下: // 兼容火狐获取一个节点的相同类型的上一个相邻节点 function perviousSiblingSameType(node , cnode ) { // 为空直接返回null if(node.previousSibling == null ) { return null ; }
先按W3C的规范来说这两个方法应该返回的内容吧: querySelector: return the first matching Element node within the node's subtrees. If there is no such node, the method must r
前台代码 实现代码如下: //客户端捕捉事件 function CheckEvent() { var objNode = event.srcElement; if (objNode.tagName == "INPUT" if (objNode.checked == true) { setChil
实现代码如下: content1 2009-10-11 title2 content2 2009-11-11 */ /* 使用DOM复制(克隆)指定节点名数据到新的XML文件中 ,用到三个类的相关知识点 : DOMDocument - DOMNodeList - DOMNode 1.
这里把符合以下条件的对象称为伪数组 1,具有length属性 2,按索引方式存储数据 3,不具有数组的push,pop等方法 如 1,function内的arguments 。 2,通过document.forms,Form.elements,Select.options,document.getE
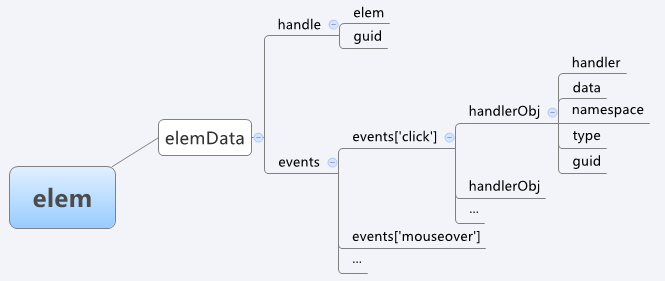
这篇看看其源码,这个add定义如下(省略大部分) 实现代码如下: add: function( elem, types, handler, data ) { if ( elem.nodeType === 3 || elem.nodeType === 8 ) { return; } ... }定义了四
主类别表名:Navtion_TopSubject 主键fTopID Char(36) 次类别表名:Navtion_NodeSubject 外键同上 内容表名:tText 外键同上 实现代码如下: // ------------- 代码开始 -------------------- CREATE TR
第十章 DOM DOM是针对XML和HTML文档的一个API:即规定了实现文本节点操控的属性、方法,具体实现由各自浏览器实现。 1. 节点层次 1) 文档节点:document,每个文档的根节点。 2) 文档元素:即元素,文档最外层元素,文档节点第一个子节点。 3) Node类型: ①Node是DO