
mongoDB中CRUD的深入讲解
前言今天开始接触非关系型数据库的mongoDB,现在将自己做的笔记发出来,供大家参考,也便于自己以后忘记了可以查看。首先,mongoDB,是一种数据库,但是又区别与mysql,sqlserver、orcle等关系数据库,在优势上面也略高一筹;至于为什么会这么说呢?很简单,我们来举两个例子:1.在存储
前言今天开始接触非关系型数据库的mongoDB,现在将自己做的笔记发出来,供大家参考,也便于自己以后忘记了可以查看。首先,mongoDB,是一种数据库,但是又区别与mysql,sqlserver、orcle等关系数据库,在优势上面也略高一筹;至于为什么会这么说呢?很简单,我们来举两个例子:1.在存储
创建爬虫项目doubanscrapy startproject douban设置items.py文件,存储要保存的数据类型和字段名称# -*- coding: utf-8 -*-import scrapyclass DoubanItem(scrapy.Item):title = scrapy.Fie
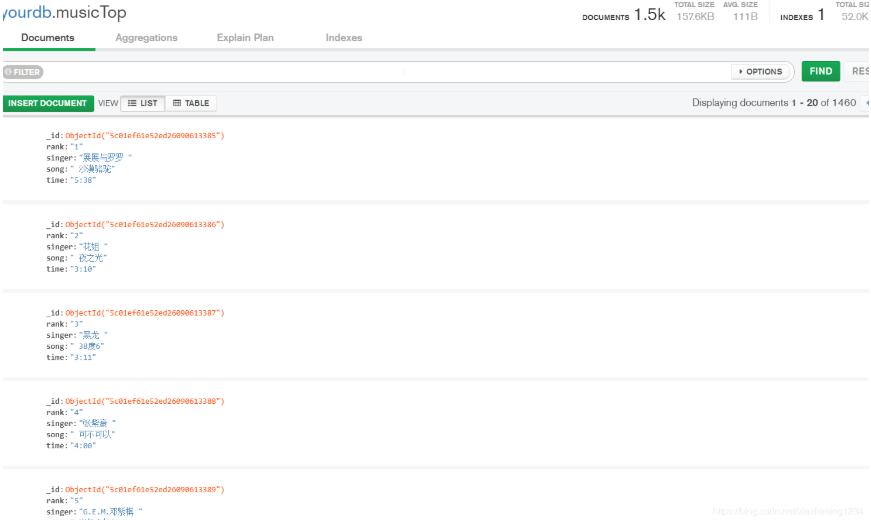
爬取TOP500的音乐信息,包括排名情况、歌曲名、歌曲时间。网页版酷狗不能手动翻页进行下一步的浏览,仔细观察第一页的URL:http://www.kugou.com/yy/rank/home/1-8888.html这里尝试将1改为2,再进行浏览,恰好是第二页的信息,再改为3,恰好是第三页的信息,多次
我们一般通过表达式$sum来计算总和。因为MongoDB的文档有数组字段,所以可以简单的将计算总和分成两种:1,统计符合条件的所有文档的某个字段的总和;2,统计每个文档的数组字段里面的各个数据值的和。这两种情况都可以通过$sum表达式来完成。以上两种情况的聚合统计,分别对应与聚合框架中的 $grou
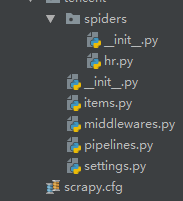
创建项目scrapy startproject zhaoping创建爬虫cd zhaopingscrapy genspider hr zhaopingwang.com目录结构items.pytitle = scrapy.Field()position = scrapy.Field()publish_
前言因为之前没用过mongo,所以最近的开发踩了不少坑,现在熟练了不少。mongo在许多地方用起来还有许多不如意的地方,比如不知道如何加行锁,虽然mongo本身可以加写锁, 多写的时候保证原子性,但不能向mysql在事务中 select ... for update 这样加锁, 这样可以在应用代码中
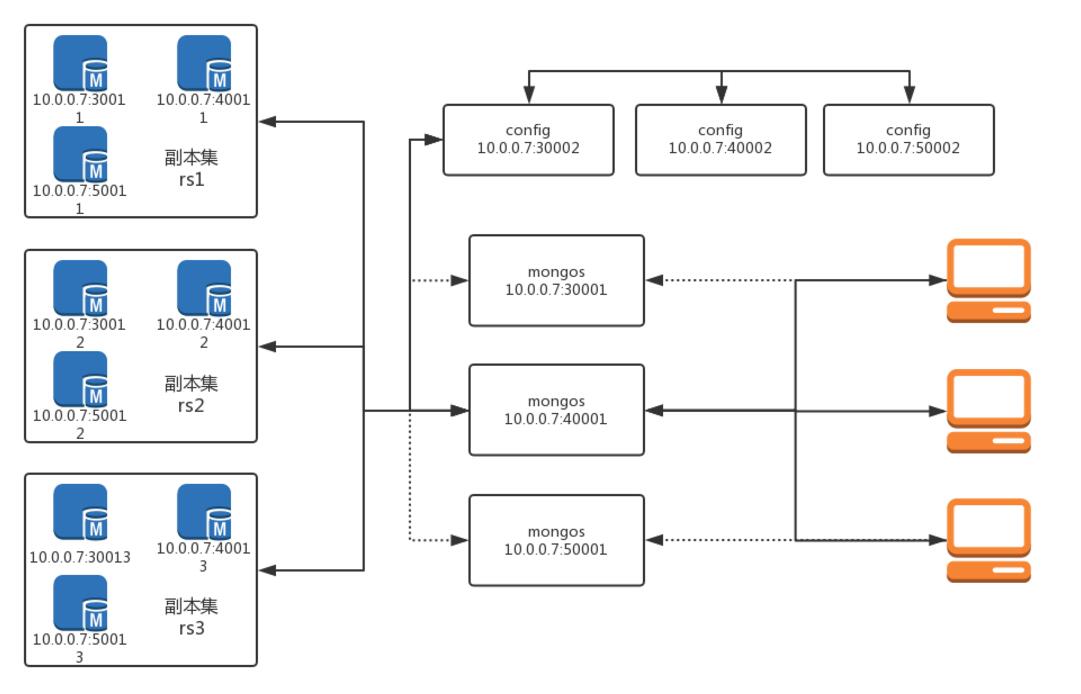
配置脚本以及目录下载:点我下载一、规划好端口ip架构图如下,任意抽取每个副本集中的一个分片(非仲裁节点)可以组成一份完整的数据。1. 第一个副本集rs1share1 10.0.0.7:30011:/data/share_rs/share_rs1/share1/data/share2 10.0.0.7
前言任何一种数据库都有各种各样的日志,MongoDB也不例外。MongoDB中有4种日志,分别是系统日志、Journal日志、oplog主从日志、慢查询日志等。这些日志记录着MongoDB数据库不同方面的踪迹。下面分别介绍这几种日志。系统日志系统日志在MongoDB数据库中很重要,它记录着Mongo
MongoDB按照天数或小时聚合需求最近接到需求,需要对用户账户下的设备状态,分别按照天以及小时进行聚合,以此为基础绘制设备状态趋势图.实现思路是启动定时任务,对各用户的设备状态数据分别按照小时以及天进行聚合,并存储进数据库中供用户后续查询.涉及到的技术栈分别为:Spring Boot,MongoD
MongoDB中存在一种索引,叫做TTL索引(time-to-live index,具有生命周期的索引),这种索引允许为每一个文档设置一个超时时间。一个文档达到预设置的老化程度后就会被删除。数据到期对于某些类型的信息非常有用,例如机器生成的事件数据,日志和会话信息,这些信息只需要在数据库中保存有限的