
使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解
下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最基础的内容html_doc = """The Dormouse's storyThe Dormouse's storyOnce upon a time there were three little
下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最基础的内容html_doc = """The Dormouse's storyThe Dormouse's storyOnce upon a time there were three little
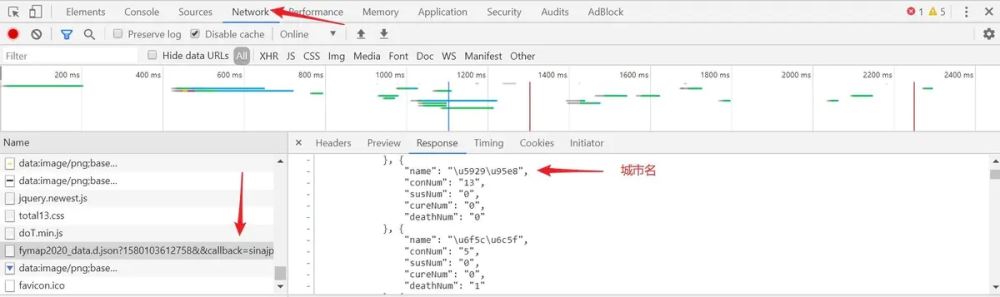
最近一周每天早上起来第一件事,就是打开新闻软件看疫情相关的新闻。了解下自己和亲友所在城市的确诊人数,但纯数字还是缺乏一个直观的概念。那我们来做一个吧。至于数据,从各大网站的实时疫情页面就可以拿到。以某网站为例,用requests拿到html后,发现并没有数据。不要慌,那证明是个javascript渲
一、介绍BeautifulSoup库是灵活又方便的网页解析库,处理高效,支持多种解析器。利用它不用编写正则表达式即可方便地实现网页信息的提取。Python常用解析库解析器使用方法优势劣势Python标准库BeautifulSoup(markup, “html.parser”)Python的内置标准库

一、建立网页 function messageBox(message){alert(message);} javascript访问C#代码 二、建立Windows应用程序 1.创建Windows应用程序项目 2.在Form1窗体中添加WebBrowser控件 3.在Form1类的上方添加 [

有的网站出于各种各样的原因,在IIS中修改了动态页面的默认后缀,asp时代就有人在服务器上修改配置,把html后缀的文件当作asp文件来解析:也就是说,asp程序(后缀为.asp)可以保存为一个.htm后缀的文件放到服务器上WEB目录下,而服务器照样将之当作asp程序来解释处理,生成结果。这样对访问
void Page_Load(Object sender,EventArgs e){//获取要加密的字段,并转化为Byte[]数组byte[] data=System.Text.Encoding.Unicode.GetBytes(source.Text.ToCharArray());//建立加密服务
思路 1. 利用如Dw-Mx这样的工具生成html格式的模板,在需要添加格式的地方加入特殊标记(如$htmlformat$),动态生成文件时利用代码读取此模板,然后获得前台输入的内容,添加到此模板的标记位置中,生成新文件名后写入磁盘,写入后再向数据库中写入相关数据。 2. 使用后台代码硬编码

今天开发中涉及到对一个层的信息控制,就是控制一个层中显示什么信息,查找资料才知道使用innerHTML属性来控制层的值,这个innerHTML跟表单里面的value属性有点类似,能够控制层的显示值。比如说我一个div层里本来没有值,我处罚一个事件后要显示值,那么就能够使用innerHTML属性了,其
JavaScript版代码高亮JavaScript版代码高亮显示/**** ======================================================================================** 类名:CLASS_HIGHLIGHT** 功能
传统的HTML页面中连动下拉框采用了两种方法:1)直接将下拉框中的内容hardcode于html的javascript中,调用javascript函数循环写入下拉框中。这种方法不适用于下拉框内容经常改变的情况。因为数据源和javascript程序写死在同一页面。List上海江西==所有地区==2)j