
TensorFlow实现从txt文件读取数据
TensorFlow从txt文件中读取数据的方法很多有种,我比较常用的是下面两种:【1】np.loadtxtimport numpy as npdata=np.loadtxt('ex1data1.txt',dtype='float',delimiter=',')X_train=data[:,0]y_
TensorFlow从txt文件中读取数据的方法很多有种,我比较常用的是下面两种:【1】np.loadtxtimport numpy as npdata=np.loadtxt('ex1data1.txt',dtype='float',delimiter=',')X_train=data[:,0]y_
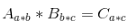
Tensorflow二维、三维、四维矩阵运算(矩阵相乘,点乘,行/列累加)1. 矩阵相乘 根据矩阵相乘的匹配原则,左乘矩阵的列数要等于右乘矩阵的行数。在多维(三维、四维)矩阵的相乘中,需要最后两维满足匹配原则。可以将多维矩阵理解成:(矩阵排列,矩阵),即后两维为矩阵,前面的维度为矩阵的排列。比如对于
tensorflow对图像进行多个块的行列拼接tf.concat(), tf.stack()在深度学习过程中,通过卷积得到的图像块大小是8×8×1024的图像块,对得到的图像块进行reshape得到[8×8]×[32×32],其中[8×8]是图像块的个数,[32×32]是小图像的大小。通过tf.co

今天在写样式的时候突然需要实现样式css溢出隐藏并显示省略号.话不多说.单行文本溢出隐藏,单行文本溢出隐藏显示省略号
这个问题是在著名的问答网站——stackoverflow上看到的。 之前也看到过JavaScript的这个问题,但是没有深入了解,今天在StackOverflow上看到了答案,感觉不错,记下来分享给大家。问题的描述是这样的: 实现代码如下: console.log(10..toString());/
测试环境:ie8 ff13.0.1 chrome22 可以将分页获取的内容依次填入四个div中,瀑布流的分页可以以多页(比如5页)为单位二次分页,这样可以减少后台算法的复杂度 实现代码如下: waterfall flow body{margin:0px;} #main{width:840
实现代码如下: Untitled Page .w_con{ width:400px; height:160px; overflow:hidden; border:1px solid #333;} #w_slid{ width:100%;} #w_slid li{ width:100%; h
实现代码如下: demo ul,li,img{margin:0;padding:0;border:0;} #list{height:250px;list-style-type:none;overflow:hidden;} var odiv=document.getElement
实现代码如下: body{ font:12px/1.5 Tahoma; } #gannt_left{ width:500px; } #left-scroll-panel{ width:520px; height:100px; overflow-y: auto; } table{ tabl
实现代码如下: table {width:200px;table-layout:fixed;} td {white-space:nowrap;overflow:hidden;word-break:keep-all;} 测试测试测试测试测试测试测试测试测试测试 测试测试测试测试测试测试测