python 中文乱码问题深入分析
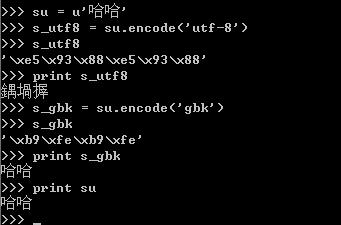
在本文中,以'哈'来解释作示例解释所有的问题,“哈”的各种编码如下: 1. UNICODE (UTF8-16),C854; 2. UTF-8,E59388; 3. GBK,B9FE。 一、python中的str和unicode 一直以来,python中的中文编码就是一个极为头大的问题,经常抛出编码转
在本文中,以'哈'来解释作示例解释所有的问题,“哈”的各种编码如下: 1. UNICODE (UTF8-16),C854; 2. UTF-8,E59388; 3. GBK,B9FE。 一、python中的str和unicode 一直以来,python中的中文编码就是一个极为头大的问题,经常抛出编码转
_jQuery = window.jQuery; _$ = window.$; 这两个变量是jQuery唯一使用的两个全局变量。在jQuery.noConflict()函数中,会把这两个变量恢复回去。 对于浏览器检测,jQuery使用的是检查UserAgent,而没有使用特性检测。 rwebkit
当在php中使用mb_detect_encoding函数进行编码识别时,很多人都碰到过识别编码有误的问题,例如对与GB2312和UTF- 8,或者UTF-8和GBK(这里主要是对于cp936的判断),网上说是由于字符短是,mb_detect_encoding会出现误判。 例如: 实现代码如下: $e
大家以后在编写过程中, 一定要记得定义字符类型。mysql_query("set names 'gbk'") 解决的方法就这么简单。 今天做了一个数据库查询,放出代码。 实现代码如下: "; for($cout=0;$cout"; echo "city: $city"; echo "name: $n
使用方法: 实现代码如下: $s ='中国'; $os = new String( $s ); echo $os->decode('gbk') ,''; echo $os->decode('gbk')->encode('md5'),'';代码 实现代码如下: class Strin
实现代码如下: $cn = mysql_connect('127.0.0.1','root','root') or die('database connect fail'); mysql_select_db('test',$cn); mysql_query("set names 'gbk'"); /
编码范围1. GBK (GB2312/GB18030) \x00-\xff GBK双字节编码范围 \x20-\x7f ASCII \xa1-\xff 中文 \x80-\xff 中文 2. UTF-8 (Unicode) \u4e00-\u9fa5 (中文) \x3130-\x318F (韩文 \xA
指定的代码页特性无效。 codepage属性:是指出网页的代码页 如果制作的网页脚本与WEB服务端的默认代码页不同,则必须指明代码页: 实现代码如下: codepage=936 简体中文GBK codepage=950 繁体中文BIG5 codepage=437 美国/加拿大英语 codepage=
php的header来定义一个php页面为utf编码或GBK编码 php页面为utf编码 header("Content-type: text/html; charset=utf-8"); php页面为gbk编码 header("Content-type: text/html; charset=gb
只是中文出现乱码时,在链接数据库后面,加上这一句 utf8的话 mysql_query("SET NAMES 'utf8'"); gbk的话 mysql_query("SET NAMES 'gbk'");