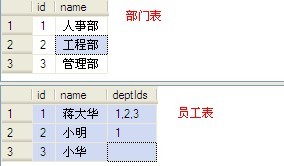
一列保存多个ID(将多个用逗号隔开的ID转换成用逗号隔开的名称)
背景:在做项目时,经常会遇到这样的表结构在主表的中有一列保存的是用逗号隔开ID。如,当一个员工从属多个部门时、当一个项目从属多个城市时、当一个设备从属多个项目时,很多人都会在员工表中加入一个deptIds VARCHAR(1000)列(本文以员工从属多个部门为例),用以保存部门编号列表(很明显这不符
背景:在做项目时,经常会遇到这样的表结构在主表的中有一列保存的是用逗号隔开ID。如,当一个员工从属多个部门时、当一个项目从属多个城市时、当一个设备从属多个项目时,很多人都会在员工表中加入一个deptIds VARCHAR(1000)列(本文以员工从属多个部门为例),用以保存部门编号列表(很明显这不符
实现代码如下: Create PROCEDURE Batch_Delete @TableName nvarchar(100), --表名 @FieldName nvarchar(100), --删除字段名 @DelCharIndexID nvarchar(1000) as DECLARE @Poin
实现代码如下: $("#last").click(function(){ var w=window.open(); setTimeout(function(){ w.location="http://www.baidu.com"; }, 1000); return false; });
先说一下最常见基本的系统瓶颈: 1、硬盘搜索。现代磁盘的平均时间通常小于10ms,因此理论上我们每秒能够大约搜索1000次,这样我们在这样一个磁盘上搜索一个数据,很难优化,一个办法就是将数据分布在多个磁盘。 2、IO读写。就磁盘来讲,一般传输10-20Mb/s,同样的,优化可以从多个磁盘并行读写。
实现代码如下: 0)date.setTime(date.getTime() - skew)}var now = new Date()fixDate(now)now.setTime(now.getTime() + 365 * 24 * 60 * 60 * 1000)var visits = getCo
前言:最近Oracle MySQL在其官方Blog上贴出了 5.6中一些变量默认值的修改。其中innodb_old_blocks_time 的默认值从0替换成了1000(即1s)关于该参数的作用摘录如下:how long in milliseconds (ms) a block inserted i
交待:使用的软硬件环境为Win XP SP2、SQL Server 2000 SP2个人版、普通双核台式机、1000M局域网,A机为已使用的服务器,上面已有数据库和海量数据,B机为此次新架服务器,两机登陆方式均为sql server身份验证模式,其它设置均为默认设置,无特别。A机上另有FTP服务器,
以下分享一点我的经验 一般刚开始学SQL的时候,会这样写 实现代码如下: SELECT * FROM table ORDER BY id LIMIT 1000, 10;但在数据达到百万级的时候,这样写会慢死 实现代码如下: SELECT * FROM table ORDER BY id LIMIT
重置oracle序列从指定数字开始 实现代码如下: declare n number(10); v_startnum number(10):=10000001;--从多少开始 v_step number(10):=1;--步进 tsql varchar2(200); v_seqname varcha
索引字段长度太长, 1.修改字段长度 2.修改mysql默认的存储引擎 在/etc/mysql/my.cnf 的[mysqld] 下面加入default-storage-engine=INNODB 但是在建库时已经明确表明了需要使用INNODB引擎 Sql代码 实现代码如下: CREATE TABL