正则表达式之 贪婪与非贪婪模式详解(概述)
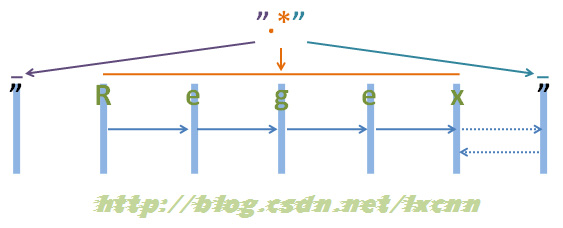
1 概述 贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。非贪婪模式只被部分NFA引擎所支持。 属于贪婪模式的量词,也叫做匹配优先量词,包括: “{m,n}”、“{m,}”、“?”
1 概述 贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。非贪婪模式只被部分NFA引擎所支持。 属于贪婪模式的量词,也叫做匹配优先量词,包括: “{m,n}”、“{m,}”、“?”

常用到的元字符有: . 查找单个字符,除了换行和行结束符; \w 匹配字母、汉字、数字、下划线等符号; \s 匹配空白符(包含空格、制表符等); \d 匹配数字; \b 匹配位于单词的开头或结尾的匹配; 常用的量词有: ^n 匹配任何开头为 n 的字符串; n$ 匹配任何结尾为 n 的字符串; n+
先扫盲一下什么是正则表达式的贪婪,什么是非贪婪?或者说什么是匹配优先量词,什么是忽略优先量词? 好吧,我也不知道概念是什么,来举个例子吧。 某同学想过滤之间的内容,那是这么写正则以及程序的。 实现代码如下: $str = preg_replace('%.+?%i','',$str);//非贪婪看起来
关于“回溯”我也是第一次接触,对它也不算很了解。下面就把我所了解的做为一个心德记录下来,以备查看。 我们所使用的正则表达式的匹配基础大概分为:优先选择最左端(最靠开头)的匹配结果和标准的匹配量词(*、+、?和{m, n})是匹配优先的。 “优先选择最左端的匹配”顾名思义就是从字符串的起始位置开始匹配