oracle sql 去重复记录不用distinct如何实现
用distinct关键字只能过滤查询字段中所有记录相同的(记录集相同),而如果要指定一个字段却没有效果,另外distinct关键字会排序,效率很低 。 select distinct name from t1 能消除重复记录,但只能取一个字段,现在要同时取id,name这2个字段的值。 select
用distinct关键字只能过滤查询字段中所有记录相同的(记录集相同),而如果要指定一个字段却没有效果,另外distinct关键字会排序,效率很低 。 select distinct name from t1 能消除重复记录,但只能取一个字段,现在要同时取id,name这2个字段的值。 select
注:此处“重复”非完全重复,意为某字段数据重复 HZT表结构 ID int Title nvarchar(50) AddDate datetime 数据 一. 查找重复记录 1. 查找全部重复记录 Select * From 表 Where 重复字段 In (Select 重复字段 Fr
现在让我们来看在SQL SERVER 2008中如何删除这些记录, 首先,可以模拟造一些简单重复记录:实现代码如下: Create Table dbo.Employee ( [Id] int Primary KEY , [Name] varchar(50), [Age] int, [Sex] bit
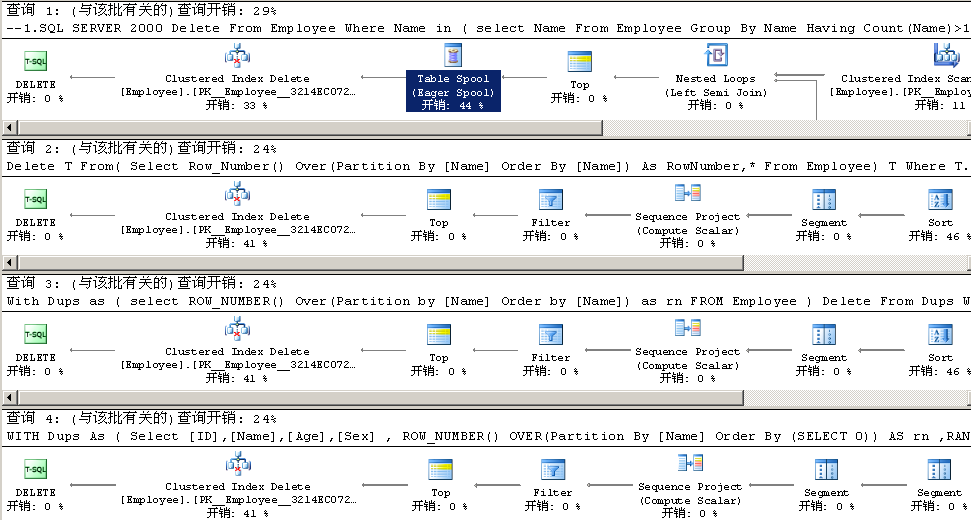
下面我们来看下,如何利用它来删除一个表中重复记录: 实现代码如下: If Exists(Select * From tempdb.Information_Schema.Tables Where Table_Name Like '#Temp%') Drop Table #temp Create Tab
MySQL 当记录不存在时插入(insert if not exists) 在 MySQL 中,插入(insert)一条记录很简单,但是一些特殊应用,在插入记录前,需要检查这条记录是否已经存在,只有当记录不存在时才执行插入操作,本文介绍的就是这个问题的解决方案。 在 MySQL 中,插入(inser
我们先看一下相关数据结构的知识。 在学习线性表的时候,曾有这样一个例题。 已知一个存储整数的顺序表La,试构造顺序表Lb,要求顺序表Lb中只包含顺序表La中所有值不相同的数据元素。 算法思路: 先把顺序表La的第一个元素付给顺序表Lb,然后从顺序表La的第2个元素起,每一个元素与顺序表Lb中的每一个
以下就重复记录删除的问题作一阐述。 有两个意义上的重复记录,一是完全重复的记录,也即所有字段均重复的记录,二是部分关键字段重复的记录,比如Name字段重复,而其他字段不一定重复或都重复可以忽略。 1、对于第一种重复,比较容易解决,使用 select distinct * from tableName
1、查找重复记录 ①如果只是不想在查询结果中存在重复记录, 可以加Distinct select distinct * from TestTable ②如果是想查询重复的记录及其数量 select UserID,UserName,count(*) as '记录数' from TestTable Gr
例如: id name value 1 a pp 2 a pp 3 b iii 4 b pp 5 b pp 6 c pp 7 c pp 8 c iii id是主键 要求得到这样的结果 id name value 1 a pp 3 b iii 4 b pp 6 c pp 8 c iii 方法1 del
下面先来看看例子: table表字段1字段2idname1a2b3c4c5b库结构大概这样,这只是一个简单的例子,实际情况会复杂得多。比如我想用一条语句查询得到name不重复的所有数据,那就必须使用distinct去掉多余的重复记录。select distinct name from table得到