Python的一些用法分享
1)正则表达式的使用。 实现代码如下: #正则表达式的模块 import re #正则表达式 rePattern = '.*[0-9]{4}' pattern = re.compile(rePattern) #匹配 if pattern.match(line): return True else:
1)正则表达式的使用。 实现代码如下: #正则表达式的模块 import re #正则表达式 rePattern = '.*[0-9]{4}' pattern = re.compile(rePattern) #匹配 if pattern.match(line): return True else:
譬如 限制只允许正则出现以下的 a-Z 0-9 http:// 匹配连贯 https:// 匹配连贯 / 不可连续两个出现 & % ? 不可连续两个出现 = 等号 - 中划线 _ 下划线 . 点 很重要 有如下正则符合 ^((?:http|https)://)?((?![/?]{2,})[a
如果要查找文件名中有*的文件,则需要对*进行转义,即在其前加一个\。ls \*.txt。正则表达式有以下特殊字符。需要转义 特别字符说明$匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘\n' 或 ‘\r'。要匹配 $ 字符本身,请使用 \$。
际域名格式如下: 域名由各国文字的特定字符集、英文字母、数字及“-”(即连字符或减号)任意组合而成, 但开头及结尾均不能含有“-”,“-”不能连续出现 。 域名中字母不分大小写。域名最长可达60个字节(包括后缀.com、.net、.org等)。 /^[a-z]([a-z0-9]*[-_]?[a-z0
java正则表达式提供了比较丰富的类库,大大简化了这个过程。下面列出常用的基本语法: * + ? ^ $ [] () | / \ \d \D \w \W {} {n} {n,m}等, 要注意的是“|”或符号。它可以匹配单个字符和字符串。如:t[aeio]n只匹配tan,ten,tin,ton。但不匹
具体来说,使用「(?>…)」的匹配与正常的匹配并无差别,但是如果匹配进行到此结构之后(也就是,进行到闭括号之后),那么此结构体中的所有备用状态都会被放弃(不能被回溯)。 也就是说,在固化分组匹配结束时,它已经匹配的文本已经固化为一个单元,只能作为整体而保留或放弃。括号内的子表达式中未尝试过
原文:http://blog.stevenlevithan.com/archives/algebra-with-regexes我照着原文写出的正则还真的计算出了结果。上php例子:实现代码如下: strlen($r[1]), 'y' => strlen($r[2]));} $A = 2;$B
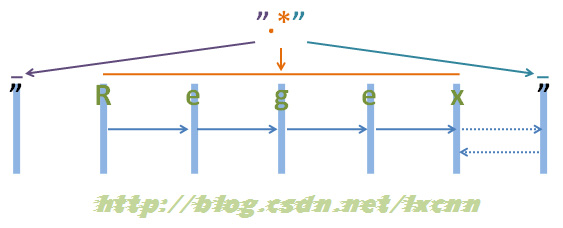
1 概述 贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。非贪婪模式只被部分NFA引擎所支持。 属于贪婪模式的量词,也叫做匹配优先量词,包括: “{m,n}”、“{m,}”、“?”
1 概述这或许会是一个让人迷惑,甚至感到混乱的话题,但也正因为如此,才有了讨论的必要。在正则中,一些具有特殊意义的字符,或是字符序列,被称作元字符,如“?”表示被修饰的子表达式匹配0次或1次,“(?i)”表示忽略大小写的匹配模式等等。而当这些元字符被要求匹配其本身时,就要进行转义处理了。不同的语言或
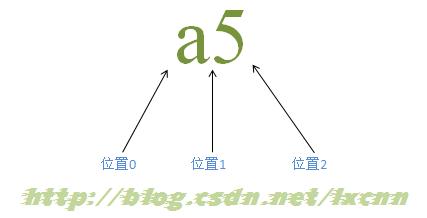
1 概述 正则表达式(Regular Expression)是一种匹配模式,描述的是一串文本的特征。 正如自然语言中“高大”、“坚固”等词语抽象出来描述事物特征一样,正则表达式就是字符的高度抽象,用来描述字符串的特征。 正则表达式(以下简称正则,Regex)通常不独立存在,各种编程语言和工具作为宿主