SQL Server误区30日谈 第6天 有关NULL位图的三个误区
这样还能减少CPU缓存命中失效的问题(点击这个链接来查看CPU的缓存是如何工作的以及MESI协议)。下面让我们来揭穿三个有关NULL位图的普遍误区。 误区 #6a:NULL位图并不是任何时候都会用到 正确 就算表中不存在允许NULL的列,NULL位图对于数据行来说会一直存在(数据行指的是堆或是聚集索
这样还能减少CPU缓存命中失效的问题(点击这个链接来查看CPU的缓存是如何工作的以及MESI协议)。下面让我们来揭穿三个有关NULL位图的普遍误区。 误区 #6a:NULL位图并不是任何时候都会用到 正确 就算表中不存在允许NULL的列,NULL位图对于数据行来说会一直存在(数据行指的是堆或是聚集索
误区 #29:可以通过对堆建聚集索引再DROP后进行堆上的碎片整理Nooooooooooooo!!!对堆建聚集索引再DROP在我看来是除了收缩数据库之外最2的事了。如果你通过sys.dm_db_index_physical_stats(或是老版本的DBCC SHOWCONTIG)看到堆上有碎片,绝对
我们知道SQLSERVER的数据行的存储有两种数据结构:A: 堆B :B树(binary 二叉树)数据按照这种两种的其中一种来排序和存储,学过数据结构的朋友应该知道二叉树,为什麽用二叉树,因为方便用二分查找法来快速找到数据。如果是堆,那么数据是不按照任何顺序排序的,也没有任何结构,数据页面也不是首尾
Windows下ORACLE完全卸载:使用OUI可以卸载数据库,但卸载后注册表和文件系统内仍会有部分残留。这些残留不仅占用磁盘空间,而且影响ORACLE的重新安装及系统性能。在WINDOWS下卸载ORACLE 10g的步骤:1 删除聚集同步服务CSS(Cluster Synchronization
一、什么是索引 减少磁盘I/O和逻辑读次数的最佳方法之一就是使用【索引】 索引允许SQL Server在表中查找数据而不需要扫描整个表。 1.1、索引的好处: 当表没有聚集索引时,成为【堆或堆表】 【堆】是一堆未加工的数据,以行标识符作为指向存储位置的指针。表数据没有顺序,也不能搜索,除非逐行遍历。
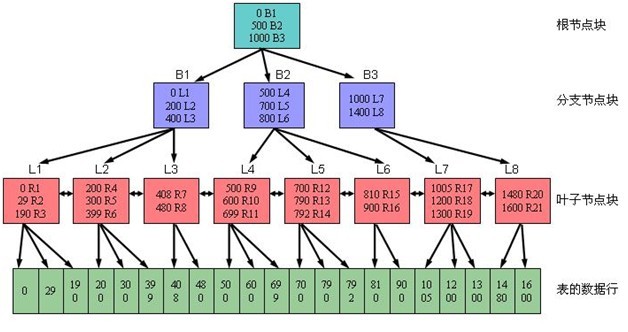
聚集索引,数据实际上是按顺序存储的,数据页就在索引页上。就好像参考手册将所有主题按顺序编排一样。一旦找到了所要搜索的数据,就完成了这次搜索,对于非聚集索引,索引是安全独立于数据本身结构的,在索引中找到了寻找的数据,然后通过指针定位到实际的数据。SQL Server中的索引使用标准的B-树来存储他们的
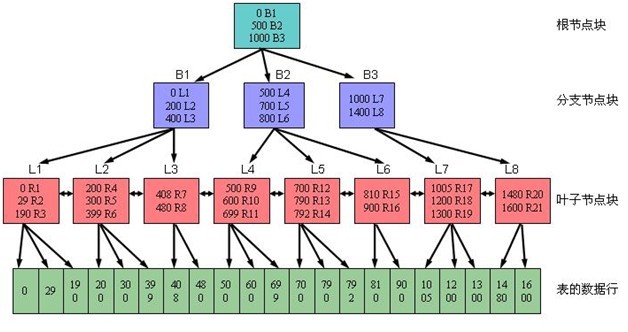
聚集索引,数据实际上是按顺序存储的,数据页就在索引页上。就好像参考手册将所有主题按顺序编排一样。一旦找到了所要搜索的数据,就完成了这次搜索,对于非聚集索引,索引是安全独立于数据本身结构的,在索引中找到了寻找的数据,然后通过指针定位到实际的数据。 SQL Server中的索引使用标准的B-树来存储他们
聚集索引:物理存储按照索引排序非聚集索引:物理存储不按照索引排序优势与缺点聚集索引:插入数据时速度要慢(时间花费在“物理存储的排序”上,也就是首先要找到位置然后插入)查询数据比非聚集数据的速度快 汉语字典的正文本身就是一个聚集索引。比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼
![sqlserver 三种分页方式性能比较[图文]](https://images.home1024.com/images/201108/2011082730028155_1.png)
Liwu_Items表,CreateTime列建立聚集索引 第一种,sqlserver2005特有的分页语法 实现代码如下: declare @page int declare @pagesize int set @page = 2 set @pagesize = 12 SET STATISTICS
数据库: 30万条,有ID列但无主键,在要搜索的“分类”字段上建有非聚集索引 过程T-SQL: 实现代码如下: /* 用户自定义函数:执行时间在1150-1200毫秒左右 CREATE FUNCTION [dbo].[gethl] (@types nvarchar(4)) RETURNS table