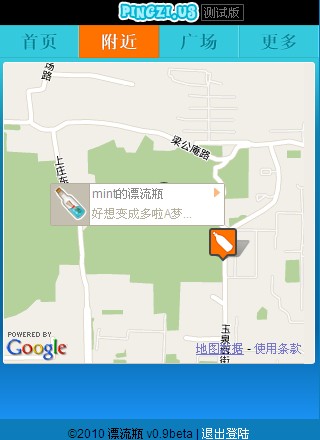
漂流瓶推送需求的逻辑实现代码
本身这两个数据之间没有关联,并且sql语句里面的排序规则不能满足要求:sql里只有数据中前一个排序条件出现相同的情况时才考虑后面的排序条件.实际情况是如果按先推送时间后距离排序的话,距离就起不了作用,反之亦然. 要让两个数据产生关联,有一种做法是将这两个数据做加法或减法后排序,但是这必须要考虑以下情
本身这两个数据之间没有关联,并且sql语句里面的排序规则不能满足要求:sql里只有数据中前一个排序条件出现相同的情况时才考虑后面的排序条件.实际情况是如果按先推送时间后距离排序的话,距离就起不了作用,反之亦然. 要让两个数据产生关联,有一种做法是将这两个数据做加法或减法后排序,但是这必须要考虑以下情
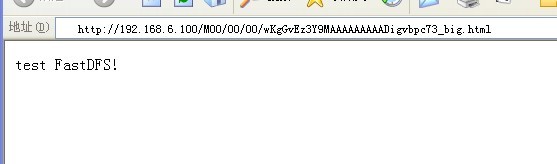
再回过头来看FastDFS更新很快,还看到fastdfs-nginx-module_v1.01.tar.gz nginx模块,所以今天在一台测试机上测试了·测试几天看稳定不稳定,在考虑换掉浪费资源的 lustre ! 环境:storage1:192.168.6.100storage2:192.168
开始以为这样的功能似乎很难,之前也做过一个百科的东西,其中也涉及到了分类的功能,不过不是无限级的分类,而是简单的实现了固定的三级分类,当时是自己设计的,想在想起来实现方法太土了,其实三级分类也只是无限级分类的一种特殊情况而已嘛。经过一段时间考虑,已经有了一些眉目,到网上一查,原来这样的东西铺天盖地,
从安全性考虑,根目录的AllowOverride属性一般都配置成不允许任何Override ,即 AllowOverride None 在 AllowOverride 设置为 None 时, .htaccess 文件将被完全忽略。当此指令设置为 All 时,所有具有 “.htaccess” 作用
当然,对于少量的字符串连接,效率并没有对程序造成多大影响,现在让我们考虑一个极端的问题:将1到100000之间的所有数字连接成一个字符串。 最简单的解决方案是直接使用&连接: 实现代码如下: begin = Timer For i = 1 To 100000 str = str &
前些天IEBlog中提到实现互通并不是只靠标准就行,其中举出了一些关于事实上的标准的考虑——所谓“事实上的标准”,也就是并非标准,但大家都遵循着它去做事情的那么一种东西。这些事实上的标准(也写作“De facto standard”)往往是在某一种事物还没有标准的时候由当事的各方相互妥协而形成的,—
我想很多人都知道,在oracle里面,存储过程里面可以传入数组(如int[]),也就是说,可以传多条记录到数据,从而一起更新。减少数据库的请求次数。 但SqlServer呢?bulk Insert这个很多人都知道,我也知道,但可惜,我从来没用过,只有导数据的时候才会考虑,但导数据DTS不是更方便吗?
1、吝啬你的代码,用最少的代码做最合适的事情; 比如你的代码中用到了很多document.getElementById(),你是否考虑写一个简单的ID选择器 实现代码如下: function $(Id) { return document.getElementById(Id); }2、吝啬你的补
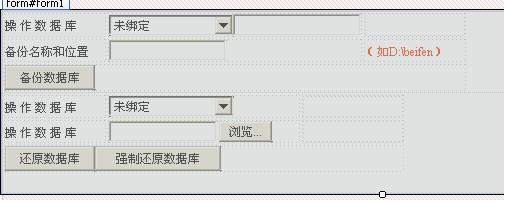
最近做的一个项目因为服务器是在特殊机房上的,因为安全方面的考虑,不能给我们开发者提供FTP服务,所以每次更新版本都得自己跑一趟,而他的机房有很远,所以我一直想能不能开发一个维护版本的系统呢,对数据库和代码进行在线更新,就不用自己跑了,于是就有了下面的尝试,在线恢复和备份SQL Server: 前台代
就是希望让Web应用程序从一开始运行到结束都一直存在,有人就说为什么不用Application呢?其实Cache是可以一段时间内自动更新数据的,而Application就无法做成这样的,另外Application在Web这种高并发的系统中一定要考虑线程安全的问题,Application本身就不是线程