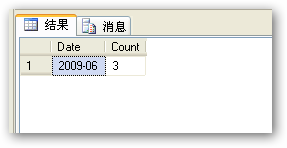
SQLserver 实现分组统计查询(按月、小时分组)
设置AccessCount字段可以根据需求在特定的时间范围内如果是相同IP访问就在AccessCount上累加。 实现代码如下:Create table Counter ( CounterID int identity(1,1) not null, IP varchar(20), AccessDat
设置AccessCount字段可以根据需求在特定的时间范围内如果是相同IP访问就在AccessCount上累加。 实现代码如下:Create table Counter ( CounterID int identity(1,1) not null, IP varchar(20), AccessDat

一般进行替换操作都这样:实现代码如下:str=str.replace(字符串一,字符串二) 不难发现一个问题,如果str要循环替换很多次,下一次替换时会累加上上次替换的内容,并且全遍历一次,如果字符串二很多,替换的过程就像阶梯效果,越来越大,所以速度越来越慢。要解决这个问题只能找另外的方法替换这种表

由于python内部的变量其实都是reference,而Tensorflow实现的时候也没有意义去判断输出是否是同一变量名,从而判定是否要新建一个Tensor用于输出。Tensorflow为了满足所有需求,定义了两个不同的函数:tf.add和tf.assign_add。从名字即可看出区别,累加应该使
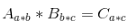
Tensorflow二维、三维、四维矩阵运算(矩阵相乘,点乘,行/列累加)1. 矩阵相乘 根据矩阵相乘的匹配原则,左乘矩阵的列数要等于右乘矩阵的行数。在多维(三维、四维)矩阵的相乘中,需要最后两维满足匹配原则。可以将多维矩阵理解成:(矩阵排列,矩阵),即后两维为矩阵,前面的维度为矩阵的排列。比如对于
Extjs的Panel和Window等组件在默认情况下是带边框的,通常情况下,单独使用没有什么关系,但是将Panel作为Window组件的子组件时就会出现双重边框的现象,如果Window组件中含有两个或者两个以上的Panel,那么Panel和Panel组件之间的边框会重复累加,也就是说会变成双重边框

先贴出完整代码. 实现代码如下: function StringBuffer() { this._strings = new Array(); } StringBuffer.prototype.append = function(str) { this._strings.push(str); //
现在有一个mysql数据库的test表里有一个duration字段,里面有三条记录: 00:22:32 13:42:21 134:42:21 表示的是时长,但是,保存类型是文本。 现在要求,用php如何将这些记录进行累加,最后显示为一个总时长为秒钟的结果? 实现代码如下: //连接数据库... 略
for循环的经典例子就是连续求和了:1+2+3+……+100,讲了一个多小时,还是有同学不会。做程序得有思想,有的同学一直敲键盘,也没搞出来。在做这个求和之前,我们要思考一下,求和其实就是连续的累加,当变量$i自增的时候肯定要与之前的数求和,那么怎么与之前的数求和呢?我们可以做一个拆分:把$i之前的
1.避免使用eval或者Function构造函数 2.避免使用with 3.不要在性能要求关键的函数中使用try-catch-finally 4.避免使用全局变量 5.避免在性能要求关键的函数中使用for-in 6.使用字符串累加计算风格 7.原操作会比函数调用快 8.设置setTimeout()
在使用Ajax提交信息时,我可能常常需要拼装一些比较大的字符串通过XmlHttp来完成POST提交。尽管提交这样大的信息的做法看起来并不优雅,但有时我们可能不得不面对这样的需求。那么JavaScript中对字符串的累加速度如何呢?我们先来做下面的这个实验。累加一个长度为30000的字符串。 测试代码