mysql数据库优化需要遵守的原则
这是我在网上看到的一篇不错的mysql数据库优化文章,内容说的很全! 1、使用索引来更快地遍历表 缺省情况下建立的索引是非群集索引,但有时它并不是最佳的。在非群集索引下,数据在物理上随机存放在数据页上。合理的索引设计要建立在对各种查询的分析和预测上。一般来说: a.有大量重复值、且经常有范围查询(
这是我在网上看到的一篇不错的mysql数据库优化文章,内容说的很全! 1、使用索引来更快地遍历表 缺省情况下建立的索引是非群集索引,但有时它并不是最佳的。在非群集索引下,数据在物理上随机存放在数据页上。合理的索引设计要建立在对各种查询的分析和预测上。一般来说: a.有大量重复值、且经常有范围查询(
假设有张学生成绩表(tb)如下: Name Subject Result 张三 语文 74 张三 数学 83 张三 物理 93 李四 语文 74 李四 数学 84 李四 物理 94 想变成 姓名 语文 数学 物理 ---------- ----------- ----------- --
聚集索引:物理存储按照索引排序非聚集索引:物理存储不按照索引排序优势与缺点聚集索引:插入数据时速度要慢(时间花费在“物理存储的排序”上,也就是首先要找到位置然后插入)查询数据比非聚集数据的速度快 汉语字典的正文本身就是一个聚集索引。比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼
管理好自己的业余时间人的差异在于业余时间。业余时间生产着人才,也生产着懒汉、酒鬼、牌迷、赌徒,由此不仅使工作业绩有别,也区分出高低优劣的人生境界。 ——著名物理学家爱因斯坦 从前,有两个道士分别住在相邻两座山上的庙里。这两座山之间有一条河,两个道士每天都会在同一时间下山去河边挑水,久而久之便成了好朋
实现代码如下: forLinux(); break; case "solaris": break; case "unix": break; case "aix": break; default: $this->forWindows(); break; } $temp_array = array
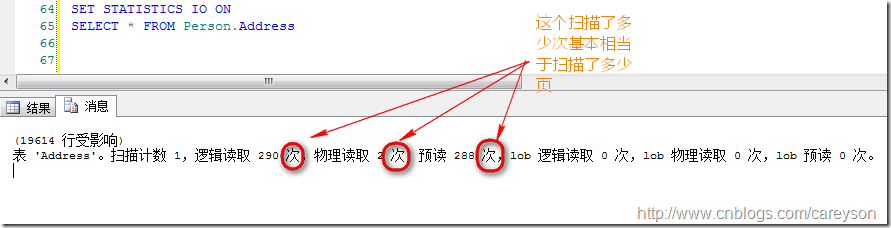
SQL SERVER数据存储的形式在谈到几种不同的读取方式之前,首先要理解SQL SERVER数据存储的方式.SQL SERVER存储的最小单位为页(Page).每一页大小为8k,SQL SERVER对于页的读取是原子性,要么读完一页,要么完全不读,不会有中间状态。而页之间的数据组织结构为B树(请参
只有mdf文件的数据库附加失败的修复 附加时报如下错误: 服务器: 消息 1813,级别 16,状态 2,行 1 未能打开新数据库 'test'。CREATE DATABASE 将终止。 设备激活错误。物理文件名 "d:\data\test_log.LDF' 可能有误。 步骤: A、用“企业管理器”
还是借用上一篇的例子: PHP代码 实现代码如下: 执行结果为: 0 5 怎么会这样呢?不应该是2个5吗?怎么会出现1个0和1个5呢? 恩,我们保留以上问题,深入分析$GLOBALS和global的原理! 我们都知道变量其实是相应物理内存在代码中的”代号”而已 引用php手册的$GLOBALS的解释
![数据库中聚簇索引与非聚簇索引的区别[图文]](https://images.home1024.com/images/201202/2012021230029693_1.jpg)
在《数据库原理》里面,对聚簇索引的解释是:聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的解释是:索引顺序与数据物理排列顺序无关。正式因为如此,所以一个表最多只能有一个聚簇索引。不过这个定义太抽象了。在SQL Server中,索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的
.net木马目前很强的, 此木马是一个.NET程序制作,如果你的服务器支持.NET那就要注意了,,进入木马有个功能叫:IIS Spy ,点击以后可以看到所有站点所在的物理路径。以前有很多人提出过,但一直没有人给解决的答案。。 防御方法: "%SystemRoot%/ServicePackFiles/