
Python爬虫库BeautifulSoup获取对象(标签)名,属性,内容,注释
一、Tag(标签)对象1.Tag对象与XML或HTML原生文档中的tag相同。from bs4 import BeautifulSoupsoup = BeautifulSoup('Extremely bold','lxml')tag = soup.btype(tag)bs4.element.Tag2
一、Tag(标签)对象1.Tag对象与XML或HTML原生文档中的tag相同。from bs4 import BeautifulSoupsoup = BeautifulSoup('Extremely bold','lxml')tag = soup.btype(tag)bs4.element.Tag2
下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最基础的内容html_doc = """The Dormouse's storyThe Dormouse's storyOnce upon a time there were three little
这篇文章主要介绍了python爬虫模块URL管理器模块用法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下URL管理器模块一般是用来维护爬取的url和未爬取的url已经新添加的url的,如果队列中已经存在了当前爬取的url了就不需要再重复爬取了,
一、介绍BeautifulSoup库是灵活又方便的网页解析库,处理高效,支持多种解析器。利用它不用编写正则表达式即可方便地实现网页信息的提取。Python常用解析库解析器使用方法优势劣势Python标准库BeautifulSoup(markup, “html.parser”)Python的内置标准库
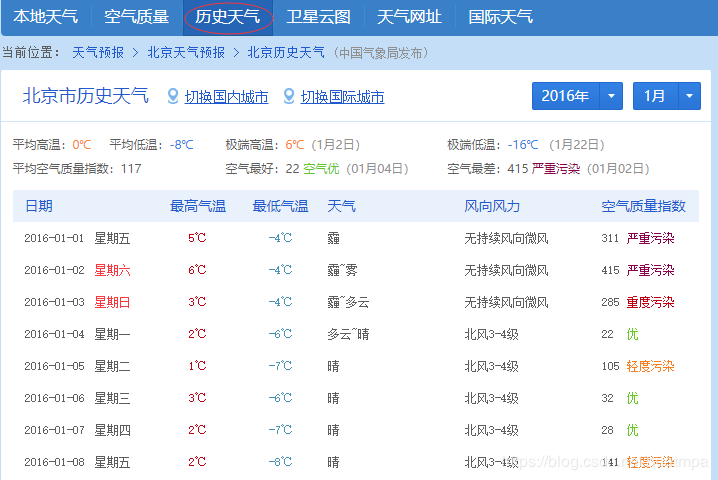
某天气网站(www.数字.com)存有2011年至今的天气数据,有天看到一本爬虫教材提到了爬取这些数据的方法,学习之,并加以改进。准备爬的历史天气爬之前先分析url。左上有年份、月份的下拉选择框,按F12,进去看看能否找到真正的url:很容易就找到了,左边是储存月度数据的js文件,右边是文件源代码,
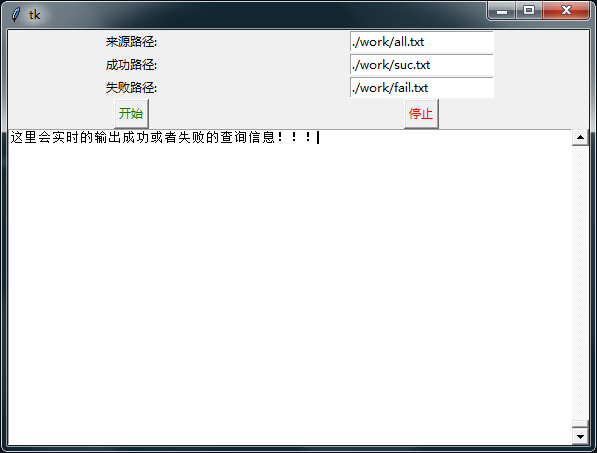
爬虫程序的核心,爬虫天眼查的公司信息类TianYanCha已经完成了,并且验证可以工作,但是给不是专业方面的人用的话,还要安装Python解释器,还没有界面是挺麻烦的,于是就想写一个简单的界面,然后打包成可执行程序给女票用。##tkinter界面由于我的界面要求很简单,只是输入两个文件路径,一个实时

本文实例讲述了Python MongoDB 插入数据时已存在则不执行,不存在则插入的解决方法。分享给大家供大家参考,具体如下:前言:想把QQ日志爬虫(Python)爬下来的日志保存到 MongoDB 里面。但 insert 的时候报错:E11000 duplicate key error colle
创建爬虫项目doubanscrapy startproject douban设置items.py文件,存储要保存的数据类型和字段名称# -*- coding: utf-8 -*-import scrapyclass DoubanItem(scrapy.Item):title = scrapy.Fie
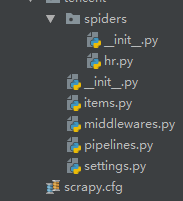
创建项目scrapy startproject zhaoping创建爬虫cd zhaopingscrapy genspider hr zhaopingwang.com目录结构items.pytitle = scrapy.Field()position = scrapy.Field()publish_
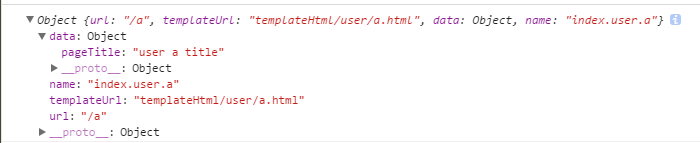
Javascript框架在处理seo方面存在问题,因为爬虫在检索seo信息的时候会读不了js给其赋的值,导致搜索引擎收录不了或者收录了无效的信息,比如收录的可能是title={{title}}这样的,下面先说如何在路由跳转时修改页面的seo信息,现在spa跳转一般用route-ui了,就以这个为基础