
TensorFlow学习之分布式的TensorFlow运行环境
当我们在大型的数据集上面进行深度学习的训练时,往往需要大量的运行资源,而且还要花费大量时间才能完成训练。1.分布式TensorFlow的角色与原理在分布式的TensorFlow中的角色分配如下:PS:作为分布式训练的服务端,等待各个终端(supervisors)来连接。worker:在TensorF
当我们在大型的数据集上面进行深度学习的训练时,往往需要大量的运行资源,而且还要花费大量时间才能完成训练。1.分布式TensorFlow的角色与原理在分布式的TensorFlow中的角色分配如下:PS:作为分布式训练的服务端,等待各个终端(supervisors)来连接。worker:在TensorF
tensorflow对图像进行多个块的行列拼接tf.concat(), tf.stack()在深度学习过程中,通过卷积得到的图像块大小是8×8×1024的图像块,对得到的图像块进行reshape得到[8×8]×[32×32],其中[8×8]是图像块的个数,[32×32]是小图像的大小。通过tf.co

实现代码如下: var dataObjCloned=JSON.parse(JSON.stringify( dataObj ))这是昨天晚上从大城小胖的微博上看到的,当时很感兴趣,就mark了下。 今天整理了下资料,分析下为什么一句话可以实现纯数据json对象的深度克隆。 1.JSON.stringi
我们知道SQLSERVER的数据行的存储有两种数据结构:A: 堆B :B树(binary 二叉树)数据按照这种两种的其中一种来排序和存储,学过数据结构的朋友应该知道二叉树,为什麽用二叉树,因为方便用二分查找法来快速找到数据。如果是堆,那么数据是不按照任何顺序排序的,也没有任何结构,数据页面也不是首尾
js一般有两种不同数据类型的值: 基本类型(包括undefined,Null,boolean,String,Number),按值传递; 引用类型(包括数组,对象),按址传递,引用类型在值传递的时候是内存中的地址。 克隆或者拷贝分为2种: 浅度克隆:基本类型为值传递,对象仍为引用传递。
1. $.find()与$.children()的区别 有如下HTML片段: 实现代码如下: 1. find() 返回元素下所有指定元素,不限制子级的深度,如: $("#div_four").find("input")//返回one、two、three三个input元素 2.childr()
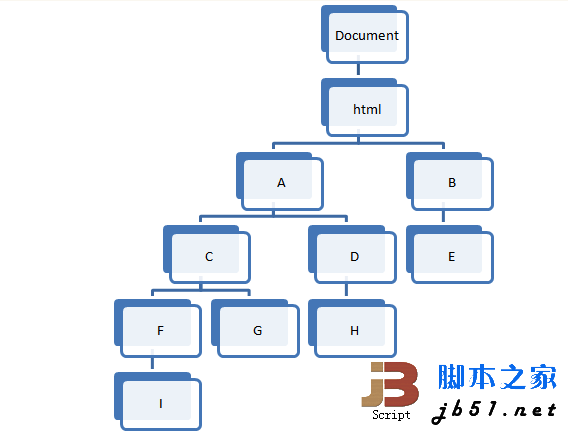
先来看概念,首先DOM是一棵树,其根节点是Document,大致可以用下图来表示: 所谓“最近的共有祖先元素”,是指给定一系列元素,找出在树中深度最大的,但同时为所有这些元素的祖先元素的元素。 比如上图中,I和G的结果为C,G和H的结果为A,D和E的结果为html,C和B的结果为html等。 测试驱
我们先来简单回顾下HTML源代码(test2.htm): 实现代码如下: $(function(){ $('#container').html('' + 'alert(typeof(jQuery.ui));'); }); 2.调试,单步跟进 逐行分析jQuery源代码是一件相当
随着Linux企业应用的不断扩展。 有大量的网络服务器都在使用Linux操作系统。Linux服务器的安全性能受到越来越多的关注。 这里根据Linux服务器受到攻击的深度以级别形式列出,并提出不同的解决方案。 随着Linux企业应用的扩展,有大量的网络服务器使用Linux操作系统。Linux服务器的安
今天,Tank问了一个问题, 对于如下的正则: 实现代码如下: /.*?/i当要匹配的字符串长度大于100014的时候, 就不会得出正确结果: 实现代码如下: $reg = "/.*?/is"; $str = "********"; //长度大于100014 $ret = preg_replace(