SQL 合并多行记录的方法总汇
SQL中合并多行记录的方法总汇: --1. 创建表,添加测试数据 CREATE TABLE tb(id int, [value] varchar(10)) INSERT tb SELECT 1, 'aa' UNION ALL SELECT 1, 'bb' UNION ALL SELECT 2, 'a
SQL中合并多行记录的方法总汇: --1. 创建表,添加测试数据 CREATE TABLE tb(id int, [value] varchar(10)) INSERT tb SELECT 1, 'aa' UNION ALL SELECT 1, 'bb' UNION ALL SELECT 2, 'a
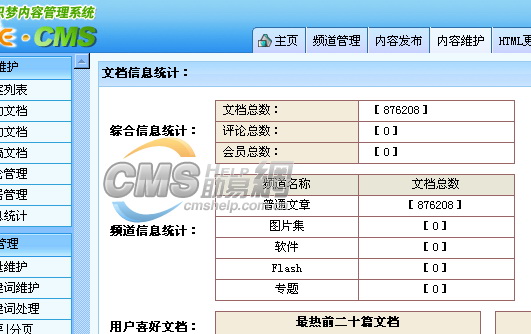
还是因为一个表的大数据造成性能严重下降?难道我们必须通过分多个表来存储才能解决问题吗?以下我们通过一个实例来解析和优化dedecms的数据管理性能,千万别让mysql当替罪羊,罪莫大焉。 测试数据是无意中得到的企业黄页的数据,数据量将近90万,都是完全真实的数据,测试使用的程序是dedecms4.0
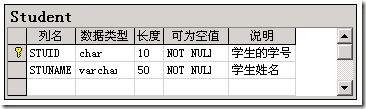
我们用到的表结构如下:三张表的关系为:现有的测试数据为:我们需要的结果是:实现代码如下:DECLARE @strSQL VARCHAR(8000) SET @strSQL = 'SELECT t.STUNAME [姓名]' SELECT @strSQL = @strSQL + ',SUM(CASE

在sql server中经常有这样的问题:一个表采用了自动编号的列之后,由于测试了好多数据,自动编号已累计了上万个。现在正是要用这个表了,测试数据已经删了,遗留下来的问题 就是 在录入新的数据,编号只会继续增加,已使用过的但已删除的编号就不能用了, 谁知道如何解决此问题?truncate命令不但会清

今天在网上看到的,一大堆测试数据,懒得看了,把结论抄下来。 比如速度可以和php一拼(虽然还是没有他快),另一种用法是 s=Join(Array("1","2","3",.....,"9999"))速度依然比"1" & "2" & "3" & .....& "9999
在sql server中经常有这样的问题:一个表采用了自动编号的列之后,由于测试了好多数据,自动编号已累计了上万个。现在正是要用这个表了,测试数据已经删了,遗留下来的问题 就是 在录入新的数据,编号只会继续增加,已使用过的但已删除的编号就不能用了, 谁知道如何解决此问题?truncate命令不但会清