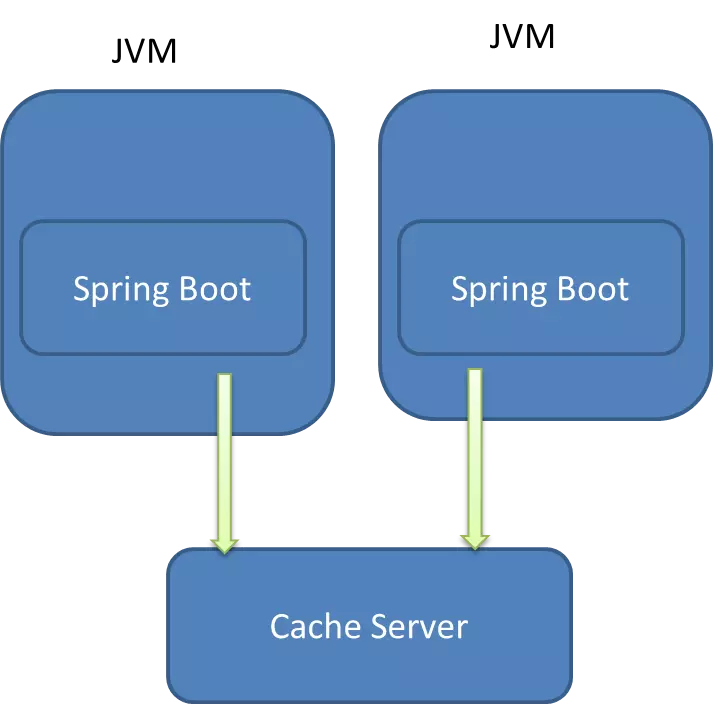
SpringBoot redis分布式缓存实现过程解析
前言应用系统需要通过Cache来缓存不经常改变得数据来提高系统性能和增加系统吞吐量,避免直接访问数据库等低速存储系统。缓存的数据通常存放在访问速度更快的内存里或者是低延迟存取的存储器,服务器上。应用系统缓存,通常有如下作用:缓存web系统的输出,如伪静态页面。缓存系统的不经常改变的业务数据,如用户权
前言应用系统需要通过Cache来缓存不经常改变得数据来提高系统性能和增加系统吞吐量,避免直接访问数据库等低速存储系统。缓存的数据通常存放在访问速度更快的内存里或者是低延迟存取的存储器,服务器上。应用系统缓存,通常有如下作用:缓存web系统的输出,如伪静态页面。缓存系统的不经常改变的业务数据,如用户权

本文实例讲述了MongoDB 复制(副本集)。分享给大家供大家参考,具体如下:replication set复制集,复制集,多台服务器维护相同的数据副本,提高服务器的可用性。MongoDB复制是将数据同步在多个服务器的过程。复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性,
在知乎上看到这样一个问题:MySQL 查询 select * from table where id in (几百或几千个 id) 如何提高效率?修改电商网站,一个商品属性表,几十万条记录,80M,索引只有主键id,做这样的查询如何提高效率?select * from table where id
以下是频繁用到的Sqlite函数,内容格式相对固定,封装一下有助于提高开发效率(^_^至少提高Codeeer的效率了) 而且,我发现Sqlite中文资料比较少,起码相对其他找起来要复杂些,服务一下大众~ 我没有封装读取部分,因为数据库读取灵活性太大,封装起来难度也大,而且就算封装好了,也难以应付所有
Js的阻塞性 Javascript 在浏览器中的性能问题,可能是最重要的可用性问题 Js的阻塞性 浏览器用单一进程来处理UI进程和Js的执行 不管是内嵌的还是外链的,下载并立即执行 因为它有可能会修改页面 页面生存周期的概念 瀑布图中看到了下载时间和executing time 在head中加入sc
1、最好不要使用引用返回值有同学在传递的参数的时候使用引用方式传递,避免了临时对象的创建,提高了效率,那么在返回值的时候能不能使用引用呢?看如下代码实现代码如下:class Rational{public:Raional( int numerator = 0, int denominator =1)
不过假设你的WordPress网站上有成百上千篇文章,而你需要进行全站范围的改动, 这时从后台逐条编辑就有点费时费力了,并且犯错的几率也会提高。 最好的方法是进入WordPress的MySQL数据库执行必要的查询(改动)。 通过MySQL可以迅速地完成以上任务,为你节省更多时间。 下面要介绍的就是一
笔者今天就谈谈自己对这两种操作模式的理解,并且给出一些可行的建议,跟大家一起来提高Oracle数据库的安全性。 一、非归档模式的利与弊。 非归档模式是指不保留重做历史的日志操作模式,只能够用于保护例程失败,而不能够保护介质损坏。如果数据库采用的是日志操作模式的话,则进行日志切换时,新的日志会直接
模态窗体已经成为Web开发人员设计界面时经常要使用的传输数据的方式。通过模态窗口,可以提高网站的可用性。正好项目的需要,有个客户想要模态弹出的窗体来提交网站的反馈,经过一番测试实现了,我使用jQuery fancybox插件来创建一个漂亮的模态窗体,提交表单的数据在服务器端实现Ajax调用。你可以在
一、抽像类(abstract) 在我们实际开发过程中,有些类并不需要被实例化,如前面学习到的一些父类,主要是让子类来继承,这样可以提高代码复用性 语法结构: 实现代码如下: abstract class 类名{ 属性 $name; 方法(){} //方法也可以为abstract 修饰符 functi