探讨select in 在postgresql的效率问题
在知乎上看到这样一个问题:MySQL 查询 select * from table where id in (几百或几千个 id) 如何提高效率?修改电商网站,一个商品属性表,几十万条记录,80M,索引只有主键id,做这样的查询如何提高效率?select * from table where id
在知乎上看到这样一个问题:MySQL 查询 select * from table where id in (几百或几千个 id) 如何提高效率?修改电商网站,一个商品属性表,几十万条记录,80M,索引只有主键id,做这样的查询如何提高效率?select * from table where id
具体来说,使用「(?>…)」的匹配与正常的匹配并无差别,但是如果匹配进行到此结构之后(也就是,进行到闭括号之后),那么此结构体中的所有备用状态都会被放弃(不能被回溯)。 也就是说,在固化分组匹配结束时,它已经匹配的文本已经固化为一个单元,只能作为整体而保留或放弃。括号内的子表达式中未尝试过
1.认为FindControl方法寻找的范围是给定Control的后代控件。 实现代码如下: 如上面代码,后台用Panel1.FindControl("Button1")寻找,认为这样范围小些可以提高效率,其实即使用TextBox1.FindControl("Button1")也一样能找
用法: 用于复杂查询时可以用临时表来暂存相关记录,能够提高效率、提高程序的可读性,类似于游标中的 my_cursor declare my_cursor cursor scroll for select 字段 from tablename 临时表分为:用户临时表和系统临时表。 系统临时表和用户临时表
(这并不意味着jQuery的性能是优秀的, 反之只能说它是一个相对封闭的库,无法从外部介入进行优化)。这篇文章就记录一次失败的优化经历。 优化思想 这一次优化的思想来自于数据库。在数据库优化的时候,我们常会说“将大量的操作放在一个事务中一起提交,能有效提高效率”。虽然对数据库不了解的我并不知道其原因
这里以拿 添加事件示例 实现代码如下: // 方式1 function addEvent(el, type, fn){ if(el.addEventListener){ el.addEventListener(type, fn, false); }else{ el.attachEvent('on'+
1.日期属性列,不会因为有分秒差别而减慢查询速度 2. 使用LIKE比较进行查询时,如果模式以特定字符串如“abc%”开头,使用索引则会提高效率;如果模式以通配符如“%xyz”开头,则索引不起作用 3. OR会引起全表扫描,且和IN的作用相当 4. 尽量少用NOT 5. EXISTS 和 IN的执行
另外在sql server内存够用的情况下索引会被放到内存中,在内存中查找自然又会提高效率;所以我们必须得合理利用索引。 1)对什么列建索引 数据库默认情况下会对主键建聚集索引,除了这个索引之外还需要在哪些列上建索引呢?这个问题只能具体情况具体分析,要看需要优化的sql语句(通常是查询次数多,查询相
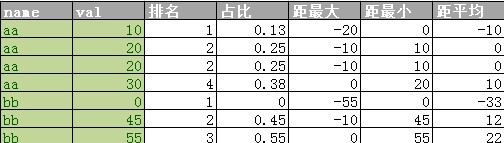
在SQLServer中我们可以用over子句中来代替子查询实现来提高效率,over子句除了排名函数之外也可以和聚合函数配合。实现代码如下: 实现代码如下:use tempdb go if (object_id ('tb' ) is not null ) drop table tb go create
定义总是很抽象。存储进程其实就是能完成一定操作的一组SQL语句,只不过这组语句是放在数据库中的(这里我们只谈SQL SERVER)。如果我们通过创建存储进程以及在ASP中调用存储进程,就可以避免将SQL语句同ASP代码混杂在一起。这样做的好处至少有三个:第一、大大提高效率。存储进程本身的执行速度非常