索引的原理及索引建立的注意事项
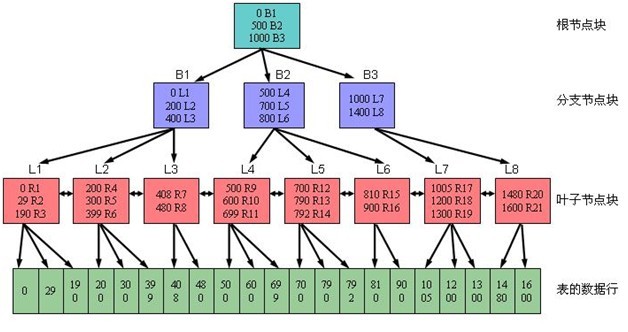
聚集索引,数据实际上是按顺序存储的,数据页就在索引页上。就好像参考手册将所有主题按顺序编排一样。一旦找到了所要搜索的数据,就完成了这次搜索,对于非聚集索引,索引是安全独立于数据本身结构的,在索引中找到了寻找的数据,然后通过指针定位到实际的数据。SQL Server中的索引使用标准的B-树来存储他们的
聚集索引,数据实际上是按顺序存储的,数据页就在索引页上。就好像参考手册将所有主题按顺序编排一样。一旦找到了所要搜索的数据,就完成了这次搜索,对于非聚集索引,索引是安全独立于数据本身结构的,在索引中找到了寻找的数据,然后通过指针定位到实际的数据。SQL Server中的索引使用标准的B-树来存储他们的
然而,微软sql server在处理这类索引时,有个重要的缺陷,那就是把本该编译成索引seek的操作编成了索引扫描,这可能导致严重性能下降 举个例子来说明问题,假设某个表T有索引 ( cityid, sentdate, userid), 现在有个分页列表功能,要获得大于某个多列复合索引V0的若干个记
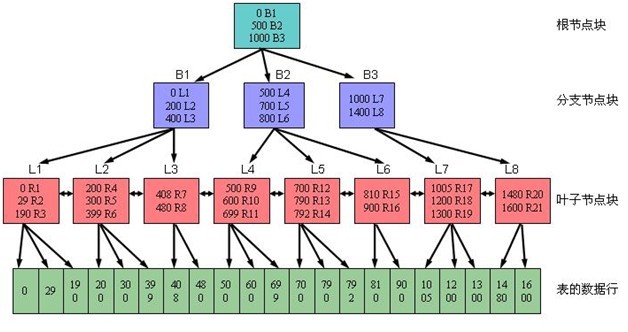
聚集索引,数据实际上是按顺序存储的,数据页就在索引页上。就好像参考手册将所有主题按顺序编排一样。一旦找到了所要搜索的数据,就完成了这次搜索,对于非聚集索引,索引是安全独立于数据本身结构的,在索引中找到了寻找的数据,然后通过指针定位到实际的数据。 SQL Server中的索引使用标准的B-树来存储他们
经常需要一个函数自执行,可惜这一种写法是错的: 实现代码如下: function(){alert(1);}();原因是前半段“function(){alert(1);}”被当成了函数声明,而不是一个函数表达式,从而让后面的“();”变得孤立,产生语法错。 按上面的分析,这一段代码虽说没有语法错,但也
由于XMLHTTP采用的是Unicode编码上传数据,而一般页面采用的是gb2312,这就造成显示页面时产生乱码.而当在获取页面时的XMLHttp返回的是utf-8编码,这就造成了显示产生乱码. 有一种解决办法就是使用encodeURIComponent加上修改 Content-Type 为 app
1.不要使用相对路径 常常会看到: require_once('../../lib/some_class.php'); 该方法有很多缺点: 它首先查找指定的php包含路径, 然后查找当前目录. 因此会检查过多路径. 如果该脚本被另一目录的脚本包含, 它的基本目录变成了另一脚本所在的目录. 另一问题,
实现代码如下: <?php $a=3; $b=6; if($a=5||$b=7){ $a++; $b++; } var_dump($a, $b);陷阱一 把$a=5、$b=7看成了$a==5、$b==7 错误结果:3,6 陷阱二 运算符的优先级,认为$a=5赋值成功$b=7没执行 错误结果:6
常见的误解有: 1. 只用 ado.net ,无法进行动态 SQL 拼接。 2. 有几个动态参数,代码的重复量就成了这些参数的不同数量的组合数,动态参数越多,重复量越大。 对于第二个问题,以下的错误代码为其证据: 实现代码如下: if(id>0 command.Parameters.Add(
6、执行环境和作用域 (1)执行环境(execution context):所有的JavaScript代码都运行在一个执行环境中,当控制权转移至JavaScript的可执行代码时,就进入了一个执行环境。活动的执行环境从逻辑上形成了一个栈,全局执行环境永远是这个栈的栈底元素,栈顶元素就是当前正在运行的
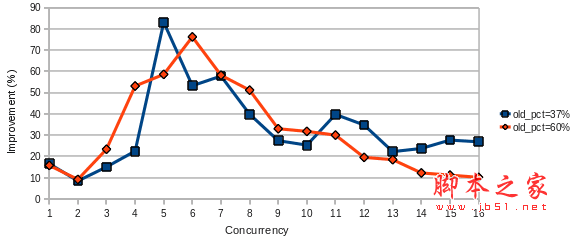
前言:最近Oracle MySQL在其官方Blog上贴出了 5.6中一些变量默认值的修改。其中innodb_old_blocks_time 的默认值从0替换成了1000(即1s)关于该参数的作用摘录如下:how long in milliseconds (ms) a block inserted i