修改mysql5.5默认编码(图文步骤修改为utf-8编码)
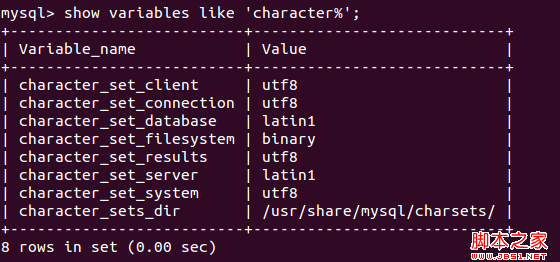
mysql数据库的默认编码并不是utf-8。安装mysql后,启动服务并登陆,使用show variables命令可查看mysql数据库的默认编码:由上图可见database和server的字符集使用了latin1编码方式,不支持中文,即存储中文时会出现乱码。以下是命令行修改为utf-8编码的过程,
mysql数据库的默认编码并不是utf-8。安装mysql后,启动服务并登陆,使用show variables命令可查看mysql数据库的默认编码:由上图可见database和server的字符集使用了latin1编码方式,不支持中文,即存储中文时会出现乱码。以下是命令行修改为utf-8编码的过程,
character-set-server/default-character-set:服务器字符集,默认情况下所采用的。 character-set-database:数据库字符集。 character-set-table:数据库表字符集。 优先级依次增加。所以一般情况下只需要设置character
实现代码如下: #coding: utf-8 import Image,ImageDraw,ImageFont,os,string,random,ImageFilter def initChars(): """ 允许的字符集合,初始集合为数字、大小写字母 usage: initChars() par
设置mysql监听外网ip实现代码如下:sudo vi /etc/my.cnfbind-address = 127.0.0.1设置mysql 字符集 charset实现代码如下:sudo vi /etc/my.cnf在[mysqld]下面加入一行character_set_server = utf8
![深入Mysql字符集设置[精华结合]](https://images.home1024.com/images/201207/2012071930030864_1.jpg)
基本概念字符(Character)是指人类语言中最小的表义符号。例如'A'、'B'等;给定一系列字符,对每个字符赋予一个数值,用数值来代表对应的字符,这一数值就是字符的编码(Encoding)。例如,我们给字符'A'赋予数值0,给字符'B'赋予数值1,则0就是字符'A'的编码;给定一系列字符并赋予对
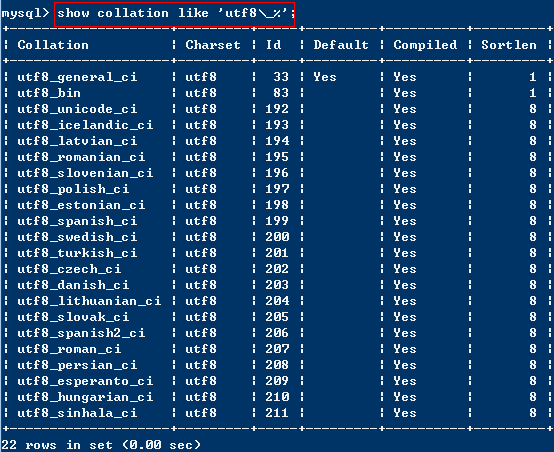
简要说明 字符集和校对规则 字符集是一套符号和编码。校对规则是在字符集内用于比较字符的一套规则。 MySql在collation提供较强的支持,oracel在这方面没查到相应的资料。 不同字符集有不同的校对规则,命名约定:以其相关的字符集名开始,通常包括一个语言名,并且以_ci(大小写不敏感)、_c
MySQL中涉及的几个字符集 character-set-server/default-character-set:服务器字符集,默认情况下所采用的。 character-set-database:数据库字符集。 character-set-table:数据库表字符集。 优先级依次增加。所以一般情况
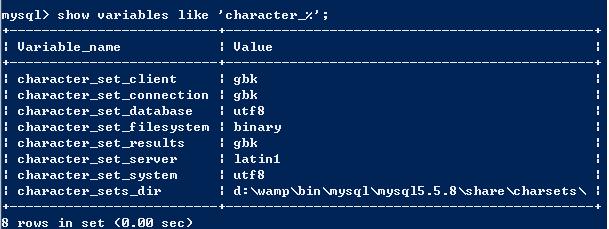
在mysql客户端与mysql服务端之间,存在着一个字符集转换器。character_set_client=>gbk:转换器就知道客户端发送过来的是gbk格式的编码character_set_connection=>gbk:将客户端传送过来的数据转换成gbk格式character_set
下面通过一些例子来说明使用正则表达式来处理一些工作中常见的问题。 1. REGEXP_SUBSTR REGEXP_SUBSTR 函数使用正则表达式来指定返回串的起点和终点,返回与source_string 字符集中的VARCHAR2 或CLOB 数据相同的字符串。 语法: --1.REGEXP_SU
GBK简体字符集的编码是同时用1个字节和2个字节来表示的。当高位是0x00~0x7f时,为一个字节,高位为0x80以上时用2个字节表示" 注:括号里面都是2进制 当你发现一个字节的内容大于0x7f,那它肯定是个(跟另外一个字节拼凑成一个)汉字,如何判断肯定大于0x7f呢? 0x7f(1111111)