
Redis分布式锁的实现方式(redis面试题)
什么是分布式锁? 要介绍分布式锁,首先要提到与分布式锁相对应的是线程锁、进程锁。线程锁:主要用来给方法、代码块加锁。当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。线程锁只在同一JVM中有效果,因为线程锁的实现在根本上是依靠线程之间共享内存实现的,比如synchronized是共
什么是分布式锁? 要介绍分布式锁,首先要提到与分布式锁相对应的是线程锁、进程锁。线程锁:主要用来给方法、代码块加锁。当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。线程锁只在同一JVM中有效果,因为线程锁的实现在根本上是依靠线程之间共享内存实现的,比如synchronized是共

前言因为之前没用过mongo,所以最近的开发踩了不少坑,现在熟练了不少。mongo在许多地方用起来还有许多不如意的地方,比如不知道如何加行锁,虽然mongo本身可以加写锁, 多写的时候保证原子性,但不能向mysql在事务中 select ... for update 这样加锁, 这样可以在应用代码中
误区 #2: DBCC CHECKDB会引起阻塞,因为这个命令默认会加锁这是错误的!在SQL Server 7.0以及之前的版本中,DBCC CHECKDB命令的本质是C语言实现的一个不断嵌套循环的代码并对表加表锁(循环嵌套算法时间复杂度是嵌套次数的N次方,作为程序员的你懂得),这种方式并不和谐,并
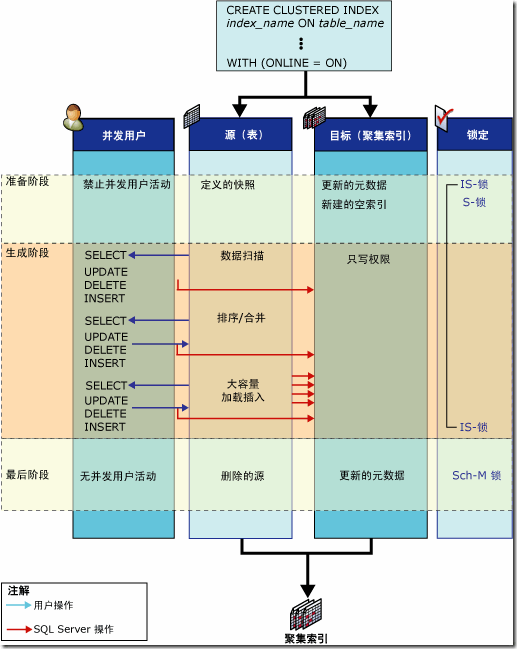
误区 #8: 在线索引操作不会使得相关的索引加锁错误!在线索引操作并不是想象的那么美好。在线索引操作会在操作开始时和操作结束时对资源上短暂的锁。这有可能导致严重的阻塞问题。在线索引操作开始时,会在被整理的资源上加一个共享的表锁,这个表锁在会在新的索引创建时、老索引进行版本扫描时一直持续。但问题是,这
误区 #30:有关备份的30个误区全是错的在开始有关备份的误区之前,如果你对备份的基础没有了解,请看之前我在TechNet Magazine的文章:Understanding SQL Server Backups。30-01)备份操作会导致阻塞不,备份不会导致对用户对象加锁,虽然备份对IO系统的负担
数据库是一个多用户使用的共享资源。当多个用户并发地存取数据时,在数据库中就会产生多个事务同时存取同一数据的情况。若对并发操作不加控制就可能会读取和存储不正确的数据,破坏数据库的一致性。 加锁是实现数据库并发控制的一个非常重要的技术。当事务在对某个数据对象进行操作前,先向系统发出请求,对其加锁。加锁后
在最近的项目中有这样的场景 1.生成文件的时候,由于多用户都有权限进行生成,防止并发下,导致生成的结果出现错误,需要对生成的过程进行加锁,只容许一个用户在一个时间内进行操作,这个时候就需要用到锁了,将这个操作过程锁起来. 2.在用了cache的时候,cache失效可能导致瞬间的多数并发请求穿透到数据
对于应用来说,我并不提倡人为给记录加锁,这样会惹来很多麻烦,况且锁并不能解决所有问题,如果你有这方面好的经验我们可以进一步交流。 对于应用来说,我并不提倡人为给记录加锁,这样会惹来很多麻烦,况且锁并不能解决所有问题,如果你有这方面好的经验我们可以进一步交流。 实现代码如下: set nocount
在网上搜了搜,有两个办法但都不太好:一个是简单的以进程ID+时间戳,或进程ID+随机数来产生近似的唯一ID,虽简单但对于追求“完美”的我不愿这样凑合,再说Apache2以后进程会维持相当长得时间,生成的ID发生碰撞的几率还是比较大的;第二个思路是通过Mysql的自增字段,这个就更不能考虑了,效率低不