
script的async属性以非阻塞的模式加载脚本
1.HTML5实现了script的async属性,这个新的属性可以让js在浏览器中以非阻塞的模式加载,另外script还有一个defer属性,这个属性目前所有浏览器都已实现(除了firefox和chrome的早期版本),IE这方面做得好,从一开始就支持些属性。 实现代码如下: //async //
1.HTML5实现了script的async属性,这个新的属性可以让js在浏览器中以非阻塞的模式加载,另外script还有一个defer属性,这个属性目前所有浏览器都已实现(除了firefox和chrome的早期版本),IE这方面做得好,从一开始就支持些属性。 实现代码如下: //async //
适用平台:WINDOWS 2K/XP HOME/PRO 适用环境:目录共享或打印机共享,经常因达到10人的连接上限,而不能给他人正常提供文件和打印共享服务 解决方法: 1、PRO版系统,修改组策略secpol.msc/本地策略/安全选项/在挂起会话之前所需时间,改为1分钟 2、使用如下脚本,每隔30
jQuery在1.5引入了Deferred对象(异步列队),当时它还没有划分为一个模块,放到核心模块中。直到1.52才分割出来。它拥有三个方法:_Deferred, Deferred与when。 出于变量在不同作用域的共用,jQuery实现异步列队时不使用面向对象方式,它把_Deferred当作一个
先说一下exit函数的用法。 作用: 输出一则消息并且终止当前脚本。 如果一段文本中包括多个以 结束的脚本,则exit退出当前所在脚本。 比如一篇php文本包括一下代码,则输出为world。 echo "world"; ?> 语法格式:void表示没有返回值。 void exit ([ st
如文本1.txt: 代码: 0000acb0h 0b0c00a000s 0000h00ga00 a0000000 通过批处理将文本所有字符串字符a前的0去除输出如下: 代码: acb0h bca000s hga00 a0000000 要求:代码简洁、高效、通用,不生成临时文件 pusofalse
先说一下采集原理: 采集程序的主要步骤如下: 一、获取被采集的页面的内容 二、从获取代码中提取所有用的数据 一、获取被采集的页面的内容 我目前所掌握的ASP常用获取被采集的页面的内容方法: 1、用serverXMLHTTP组件获取数据 实现代码如下: Function GetBody(weburl)
当访问者浏览受保护页面时,客户端浏览器会弹出对话窗口要求用户输入用户名和密码,对用户的身份进行验证,以决定用户是否有权访问页面。下面用两种方法来说明其实现原理。 一、用HTTP标头来实现 标头是服务器以HTTP协议传送HTML信息到浏览器前所送出的字串。HTTP采用一种挑战/响应模式对试图进
CollectGarbage(); setTimeout("CollectGarbage();", 1); 这里之所以使用setTimeout(),因为可以彻底回收当前所有对象,防止变量之间的引用导致释放失败,可以当作一个保障措施,按照道理来说,这里不会执行了。 使用的时候需要注意,一定在所有函数执
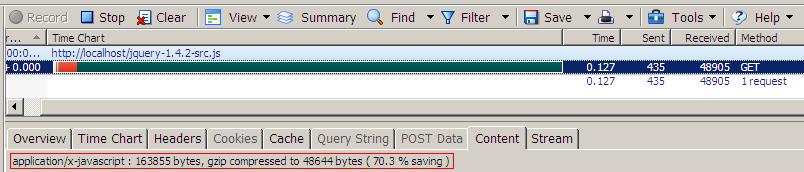
GZIP压缩gzip是目前所有浏览器都支持的一种压缩格式,IE6需要SP1及以上才支持(别说你还在用IE5,~_~)。gzip可以说是最方便而且也是最大减少响应数据量的1种方法。说它方便,是因为你不需要为它写任何额外的代码,只需要在http服务器上加上配置都行了,现在主流的http服务器都支持gzi
然而,在我所经历过的项目中,某些数据库的设计会存在一些问题,尤其普遍的就是下面将要描述的这两点,个人觉得是应该避免的误区,总结出来与大家讨论。误区之一 备用字段现象描述:在数据表中,不仅设计了当前所需要的字段,而且还在其中留出几个字段作为备用。比方说,我设计了一个人员表(Person),其中已经添加