python 算法 排序实现快速排序
QUICKSORT(A, p, r)是快速排序的子程序,调用划分程序对数组进行划分,然后递归地调用QUICKSORT(A, p, r),以完成快速排序的过程。快速排序的最差时间复杂度为O(n2),平时时间复杂度为O(nlgn)。最差时间复杂度的情况为数组基本有序的时候,平均时间复杂度为数组的数值分布
QUICKSORT(A, p, r)是快速排序的子程序,调用划分程序对数组进行划分,然后递归地调用QUICKSORT(A, p, r),以完成快速排序的过程。快速排序的最差时间复杂度为O(n2),平时时间复杂度为O(nlgn)。最差时间复杂度的情况为数组基本有序的时候,平均时间复杂度为数组的数值分布
先说一下最常见基本的系统瓶颈: 1、硬盘搜索。现代磁盘的平均时间通常小于10ms,因此理论上我们每秒能够大约搜索1000次,这样我们在这样一个磁盘上搜索一个数据,很难优化,一个办法就是将数据分布在多个磁盘。 2、IO读写。就磁盘来讲,一般传输10-20Mb/s,同样的,优化可以从多个磁盘并行读写。
HBase是Google Bigtable的开源实现,它利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协同服务。 1. 简介 HBase是一个分布式的、面向列的开源数据库,源于google的一篇论文《bigt
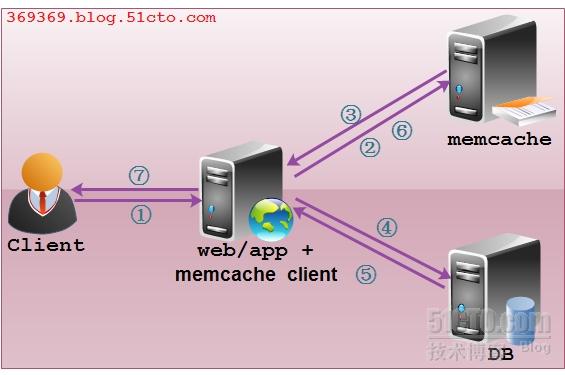
Memcached概念: Memcached是一个免费开源的,高性能的,具有分布式对象的缓存系统,它可以用来保存一些经常存取的对象或数据,保存的数据像一张巨大的HASH表,该表以Key-value对的方式存在内存中。 官网下载地址: http://www.memcached.org/ 运行环境: l
其实无论是分布式,数据缓存,还是负载均衡,无非就是改善网站的性能瓶颈,在网站源码不做优化的情况下,负载均衡可以说是最直接的手段了其实抛开这个名词,放开了说,就是希望用户能够分流,也就是说把所有用户的访问压力分散到多台服务器上,也可以分散到多个tomcat里,如果一台服务器装多个tomcat,那么即使
UUID(Universally Unique Identifier),GUID都是希望在整个时空范围内能产生唯一识别码,这在分布式计算环境下是必要的. 然而,如果仅仅是想在一个受限定的局部环境下,想生成一个"局部唯一识别码",使用UUID就是杀鸡用牛刀,这个"局部唯一识别码",我称之为LUID(L
以前一直都认为有两个字节来记录长度(长度小也可以用一个字节记录),所以这个问题当时觉得就挺无聊的不过后来群里有人给了解释,突然才发现原来事情不是这么简单 MYSQL COMPACT格式,每条记录有一个字节来表示NULL字段分布,如果表中有字段允许为空,则最大只能定到65532,如果没有字段允许为空,
![win2003分布式文件系统(dfs)配置方法[图文详解]](https://images.home1024.com/images/201210/2012101930031606_1.jpg)
在网络中,共享文件的物理位置是分散分布的,用户要询问对方的共享路径才能清楚地获得共享资源。如果想看到某局域网全部的共享文件,则需要询问每一个人,这样的操作太不方便了。根据管理员的需求,可以使用windows server 2003 自带的分布式文件系统(Dfs)来实现。Dfs可以是分布在多个服务器或
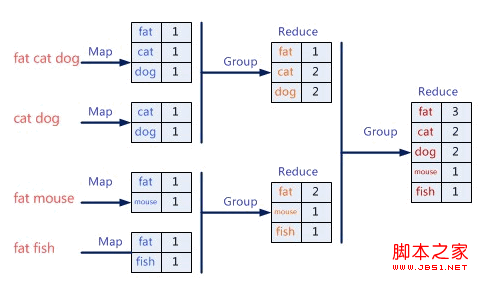
谷歌在2003到2006年间连续发表了三篇非常有影响力的文章,分别是2003年在SOSP上发布的GFS,2004年在OSDI上发布的MapReduce,以及2006年在OSDI上发布的BigTable。GFS是文件系统相关的,其对后来的分布式文件系统设计具有指导意义;MapReduce是一种并行计算
单机安装主要用于程序逻辑调试。安装步骤基本通分布式安装,包括环境变量,主要Hadoop配置文件,SSH配置等。主要的区别在于配置文件:slaves配置需要修改,另外如果分布式安装中dfs.replication大于1,需要修改为1,因为只有1个datanode. 分布式安装请参考: http://a