Mysql入门基础 数据库创建篇
1.创建数据表---基础(高手跳过) 正统方法:create [TEMPORARY] table 表名 [if not exists] (创建的列项定义) [表的选项] [分区的选项];#正统的创建方式,具体的参数,请参考mysql手册,在这里不做详细的解释,只说一些比较特别的。 例: 实现代码如下
1.创建数据表---基础(高手跳过) 正统方法:create [TEMPORARY] table 表名 [if not exists] (创建的列项定义) [表的选项] [分区的选项];#正统的创建方式,具体的参数,请参考mysql手册,在这里不做详细的解释,只说一些比较特别的。 例: 实现代码如下
对于centos、fedora和redhat的关系这里无需赘述。redhat我用不起,它的防盗版工作做的又相当好,所以我从来没有用过redhat。fedora是我刚接触linux就用的一个系统,我觉得它很好用,只是它版本更新太快了,相信很多像我这样的菜鸟都曾在新版本出来时犹豫过要不要更新。cento
1、文件和文件组的含义与关系 每个数据库有一个主数据文件.和若干个从文件。文件是数据库的物理体现。 文件组可以包括分布在多个逻辑分区的文件,实现负载平衡。文件组允许对文件进行分组,以便于管理和数据的分配/放置。例如,可以分别在三个硬盘驱动器上创建三个文件(Data1.ndf、Data2.ndf 和
终于还是找到了.现在将执行代码贴出来.希望对大家有帮助! [root@localhost ~]# fdisk /dev/hda3The number of cylinders for this disk is set to 3916.There is nothing wrong with that,
1. 纵向分表 纵向分表是指将一个有20列的表根据列拆分成两个表一个表10列一个表11列,这样单个表的容量就会减少很多,可以提高查询的性能,并在一定程度上减少锁行,锁表带来的性能损耗。 纵向分表的原则是什么呢,应该怎样拆分呢?答案是根据业务逻辑的需要来拆分,对于一张表如果业务上分两次访问某一张表其中
ROW_NUMBER()说明:返回结果集分区内行的序列号,每个分区的第一行从 1 开始。语法:ROW_NUMBER () OVER ( [ ] ) 。备注:ORDER BY 子句可确定在特定分区中为行分配唯一 ROW_NUMBER 的顺序。参数: :将 FROM 子句生成的结果集划入应用了 RO
一 .聚集索引聚集索引的页级别包含了索引键,还包含数据页,因此,关于 除了键值以外聚集索引的叶级别还存放了什么的答案就是一切,也就是说,每行的所有字段都在叶级别种。另一种说话是:数据本身也是聚集索引的一部分,聚集索引基于键值保持表中的数据有序。SQL SERVER 中,所有的聚集索引都是唯一的,如果

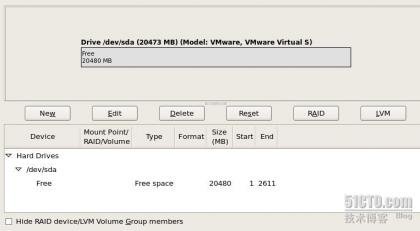
按Alt+F2切换到控制台 创建boot分区创建LVM分区转换为LMV分区格式保存查看创建物理卷创建卷组创建逻辑卷按F5设置分区格式及挂载位置
分区表的概念 分区致力于解决支持极大表和索引的关键问题。它采用他们分解成较小和易于管理的称为分区的片(piece)的方法。一旦分区被定义,SQL语句就可以访问的操作某一个分区而不是整个表,因而提高管理的效率。分区对于数据仓库应用程序非常有效,因为他们常常存储和分析巨量的历史数据。 分区表的分类 Ra
创建表分区步骤如下: 1. 创建主表 CREATE TABLE users ( uid int not null primary key, name varchar(20)); 2. 创建分区表(必须继承上面的主表) CREATE TABLE users_0 ( check (uid >= 0