
tensorflow 自定义损失函数示例代码
这个自定义损失函数的背景:(一般回归用的损失函数是MSE, 但要看实际遇到的情况而有所改变)我们现在想要做一个回归,来预估某个商品的销量,现在我们知道,一件商品的成本是1元,售价是10元。如果我们用均方差来算的话,如果预估多一个,则损失一块钱,预估少一个,则损失9元钱(少赚的)。显然,我宁愿预估多了
这个自定义损失函数的背景:(一般回归用的损失函数是MSE, 但要看实际遇到的情况而有所改变)我们现在想要做一个回归,来预估某个商品的销量,现在我们知道,一件商品的成本是1元,售价是10元。如果我们用均方差来算的话,如果预估多一个,则损失一块钱,预估少一个,则损失9元钱(少赚的)。显然,我宁愿预估多了

2具体内容 2.1使用范围SQL Server(2008开始) ;Azure SQL数据库;AzureSQL数据仓库;并行数据仓库2.2语法 是SQL Server数据库引擎评估以获取单个数据值的符号和运算符的组合。简单表达式可以是单个常量,变量,列或标量函数。运算符可用于将两个或多个简单表达式连接

SQL Server 2005开始支持XML数据类型,提供原生的XML数据类型、XML索引及各种管理或输出XML格式的函数。随着JSON的流行,SQL Server2016开始支持JSON数据类型,不仅可以直接输出JSON格式的结果集,还能读取JSON格式的数据。1 概述本篇文件将结合MSND简要分

1 概述一般地,在进行数据库设计时,应遵循三大原则,也就是我们通常说的三大范式,即第一范式要求确保表中每列的原子性,也就是不可拆分;第二范式要求确保表中每列与主键相关,而不能只与主键的某部分相关(主要针对联合主键),主键列与非主键列遵循完全函数依赖关系,也就是完全依赖;第三范式确保主键列之间没有传递
由于python内部的变量其实都是reference,而Tensorflow实现的时候也没有意义去判断输出是否是同一变量名,从而判定是否要新建一个Tensor用于输出。Tensorflow为了满足所有需求,定义了两个不同的函数:tf.add和tf.assign_add。从名字即可看出区别,累加应该使

前两天看到有人要编个考试系统,当时只是简单回了下用随机函数RND 实际一般需要从数据库中随机提取N道题目。以下代码都基于VBS;通常的编写类似这样的'产生不重复随机数function rndarray(istart,iend,sum)dim arrayid(),i,j,blnre,temp,iloo
Python操作注册表步骤之1.打开注册表对注册表进行操作前,必须打开注册表。在Python中,可以使用以下两个函数:RegOpenKey和RegOpenKeyEx。其函数原型分别如下所示。RegOpenKey(key, subKey , reserved , sam)RegOpenKeyEx(ke

一,取得原页中的图片的地址。 " '为了确保能准确地取出图片地址所以分为两层配置:首先找到里面的标签,然后再取出里面的图片地址后面的getimgs函数就是实现后一个功能的。 strs=trim(str) Set Matches =objRegExp.Execute(strs) '开始执行配置 For
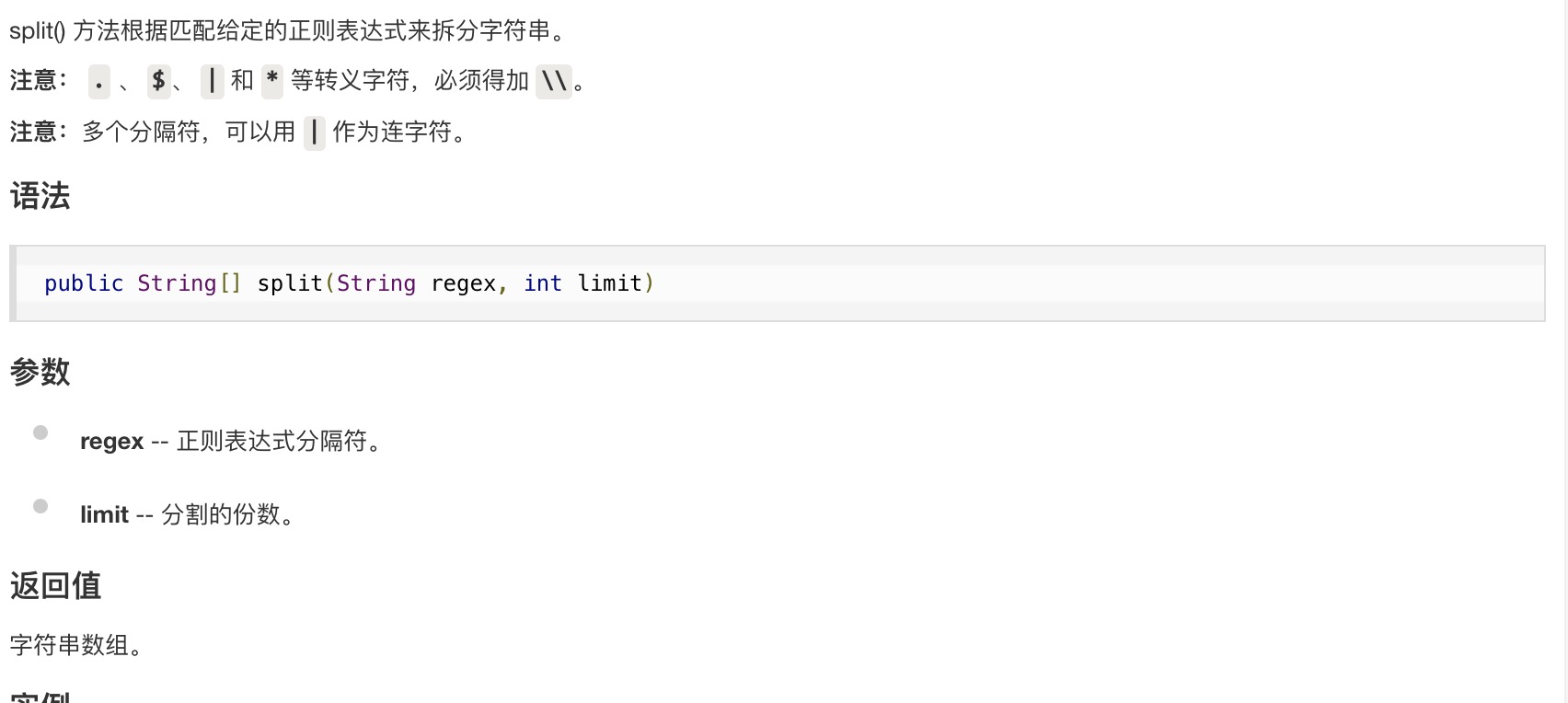
这篇文章主要介绍了java split()使用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下今天写个程序用到java里面的split()函数时,发现可以有两个参数,之前用这个函数一直是用的一个参数,今天试了下两个参数的使用,记录一下区别。下

布隆过滤器是什么布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。布隆过滤器的基本思想通过一种叫作散