SqlServer 表单查询问题及解决方法
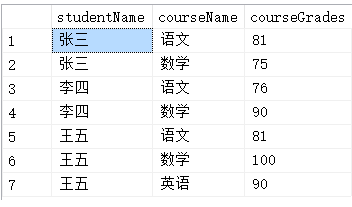
Q1:表StudentScores如下,用一条SQL语句查询出每门课都大于80分的学生姓名Q2:表DEMO_DELTE如下,删除除了自动编号不同,其他都相同的学生冗余信息Q3:Team表如下,甲乙丙丁为四个球队,现在四个球对进行比赛,用一条sql语句显示所有可能的比赛组合Q4:请考虑如下SQL语句在
Q1:表StudentScores如下,用一条SQL语句查询出每门课都大于80分的学生姓名Q2:表DEMO_DELTE如下,删除除了自动编号不同,其他都相同的学生冗余信息Q3:Team表如下,甲乙丙丁为四个球队,现在四个球对进行比赛,用一条sql语句显示所有可能的比赛组合Q4:请考虑如下SQL语句在

本文实例讲述了MongoDB 复制(副本集)。分享给大家供大家参考,具体如下:replication set复制集,复制集,多台服务器维护相同的数据副本,提高服务器的可用性。MongoDB复制是将数据同步在多个服务器的过程。复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性,
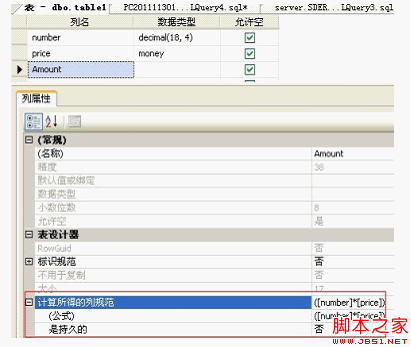
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第二部分 优化①:设计规范化表,消除数据冗余 数据库范式是确保数据库结构合理,满足各种查询需要、避免数据库操作异常的数据库设计方式。满足范式要求的表,称为规范化表,范式产生于20世纪70年代初,一般表设计满足前三范式就可以
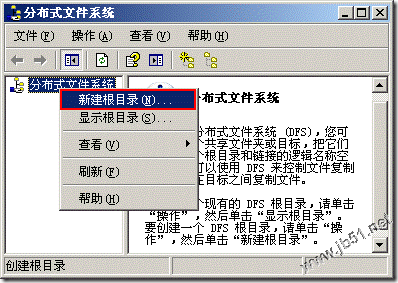
DFS介绍 使用分布式文件系统可以轻松定位和管理网络中的共享资源、使用统一的命名路径完成对所需资源院的访问、提供可靠的负载平衡、与FRS(文件复制服务)联合在多台服务器之间提供冗余、与windows权限集成以保证安全。 配置分布式文件服务器的过程很简单,可以使用"DFS管理"组件来配置,也可使用"分
Union 与 Union ALL 的作用都是合并 SELECT 的查询结果集,那么它们有什么不同呢? Union 将查询到的结果集合并后进行重查,将其中相同的行去除。缺点:效率低; 而Union ALL 则只是合并查询的结果集,并不重新查询,效率高,但是可能会出现冗余数据。 我们举个例子来说明一下
在设计主键的时候往往需要考虑以下几点: 1.无意义性:此处无意义是从用户的角度来定义的。这种无意义在一定程度上也会减少数据库的信息冗余。常常有人称呼主键为内部标识,为什么会这样称呼,原因之一在于“内部”,所谓内部从某种程度上来说就是指表记录,从大的范围来说就是数据库,如果你在设计的时候选择了对用户来
用js实现的好处是:如果一个网站中图片的hover效果比较多,可能每一个都要有css控制,那样代码有的冗余。但是有了js控制,不管有多少图片,hover效果都可以用同样的js,但是必须保证图片的out/off效果和over/on效果命名有规律性,比如: navi01_out.jpg/navi01_o
DB: 1.数据库可以适当设计一些冗余字段来减少联合查询 2.经常查询的字段要建立索引 3.查询内容尽量简洁, 比如cakephp中的查询尽量设置$this->recursive=-1,并指定fields. 4.数据库用单独的服务器,有条件的常用查询数据单独分库 5.把session等数据放在
现状: 冗余 在web开发中,我们是否常常会使用不同的编程语言实现相同的功能? 如一个文件上传功能,需要对上传文件进行文件格式限制。我们通常会使用后缀名做限制。 前端 为了用户体验,会在页面对用户选择的文件进行判断,合法才让用户可以上传。 实现代码如下: function is_filetype(f
我们先看一下相关数据结构的知识。 在学习线性表的时候,曾有这样一个例题。 已知一个存储整数的顺序表La,试构造顺序表Lb,要求顺序表Lb中只包含顺序表La中所有值不相同的数据元素。 算法思路: 先把顺序表La的第一个元素付给顺序表Lb,然后从顺序表La的第2个元素起,每一个元素与顺序表Lb中的每一个