正则表达式之 贪婪与非贪婪模式详解(概述)
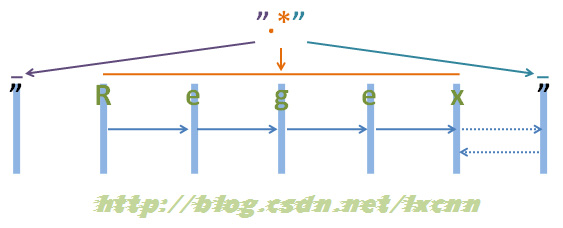
1 概述 贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。非贪婪模式只被部分NFA引擎所支持。 属于贪婪模式的量词,也叫做匹配优先量词,包括: “{m,n}”、“{m,}”、“?”
1 概述 贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。非贪婪模式只被部分NFA引擎所支持。 属于贪婪模式的量词,也叫做匹配优先量词,包括: “{m,n}”、“{m,}”、“?”
目标 使用Emberjs制作一个简单的Todo应用,实现这样一个效果:通过在文本框输入文本,创建一条代办事项,代办事项可以选择优先级,完成的事项可以删除。 准备 完成这个应用,需要做点准备: 1、创建一个html页面,暂时不管样式; 2、脚本:emberjs,handlebars、jQuery。这三
Queue ------------ 1.ArrayDeque, (数组双端队列) 2.PriorityQueue, (优先级队列) 3.ConcurrentLinkedQueue, (基于链表的并发队列) 4.DelayQueue, (延期阻塞队列)(阻塞队列实现了BlockingQueue接口)
因网站发展需要增加下载服务器赞助,我们用广告位换取资源。长期合作,以后有相关业务优先介绍给赞助idc商家。具体信息请与QQ:461478385详谈。感谢对我们的支持。
事件模型 说到事件,就要追溯到网景与微软的“浏览器大战”了。当时,事件模型还没有标准,两家公司的实现就是事实标准。网景在Navigator中实现了“事件捕获”的事件系统,而微软则在IE中实现了一个基本上相反的事件系统,叫做“事件冒泡”。这两种系统的区别在于当事件发生时,相关元素处理(响应)事件的优先
优化目标 1、减少 IO 次数 IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所决定的,大部分数据库操作中超过90%的时间都是 IO 操作所占用的,减少 IO 次数是 SQL 优化中需要第一优先考虑,当然,也是收效最明显的优化手段。 2、降低CPU计算 除了 IO 瓶颈之外,S
实现代码如下: var a; // 声明一个变量,标识符为a function a() { // 声明一个函数,标示符也为a } alert(typeof a);显示的是“function”,即function的优先级高于var。 有人觉得这是代码顺序执行的原因,即a被后执行的funcion覆盖了。
先扫盲一下什么是正则表达式的贪婪,什么是非贪婪?或者说什么是匹配优先量词,什么是忽略优先量词? 好吧,我也不知道概念是什么,来举个例子吧。 某同学想过滤之间的内容,那是这么写正则以及程序的。 实现代码如下: $str = preg_replace('%.+?%i','',$str);//非贪婪看起来
实现代码如下: interface HTMLCollection { //包含结点的个数 readonly attribute unsigned long length; //根据指定的索引index,返回相应的结点 //HTMLCollection中的结点呈树形结构,索引值index是结点深度优先
关于“回溯”我也是第一次接触,对它也不算很了解。下面就把我所了解的做为一个心德记录下来,以备查看。 我们所使用的正则表达式的匹配基础大概分为:优先选择最左端(最靠开头)的匹配结果和标准的匹配量词(*、+、?和{m, n})是匹配优先的。 “优先选择最左端的匹配”顾名思义就是从字符串的起始位置开始匹配