
js require 查找模块的顺序
require 查找模块的顺序在 Node 中模块有两类:核心模块和文件模块。在 Node 中引入模块需要三个步骤:路径分析文件定位编译执行Node 也是采用缓存优先策略,对加载过的模块都会进行缓存,以减少二次引入的开销。当然,核心模块的加载是优于文件模块加载的。require()接受一个标识符作为
require 查找模块的顺序在 Node 中模块有两类:核心模块和文件模块。在 Node 中引入模块需要三个步骤:路径分析文件定位编译执行Node 也是采用缓存优先策略,对加载过的模块都会进行缓存,以减少二次引入的开销。当然,核心模块的加载是优于文件模块加载的。require()接受一个标识符作为
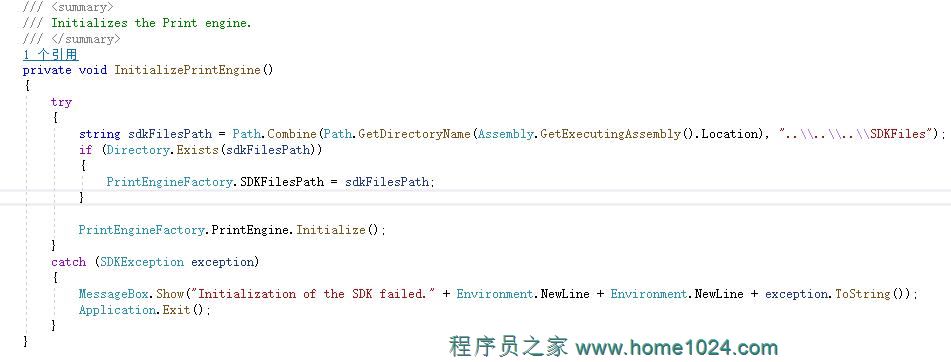
今天在用C#进行NiceLabel二次开发时,报错ErrorService.Handler property must be assigned before being used!百度没有什么资料,后面认真看了下NiceLabel官方的C#二次开发示例才知道少了引擎初始化.即加上下面一行代码即可:P

编译篇 研究Chrome ,首先得把它编译出来,这对于后续的代码分析和阅读有很大的帮助,想想自己编译出一个 Chrome 浏览器来使用,那是一件很炫的事情。 编译环境准备 Chrome的编译和 WebKit 相比起来,难度上来说,简直是一元二次方程求解和偏微分方程求解的对比(我到现在还没有完整的把
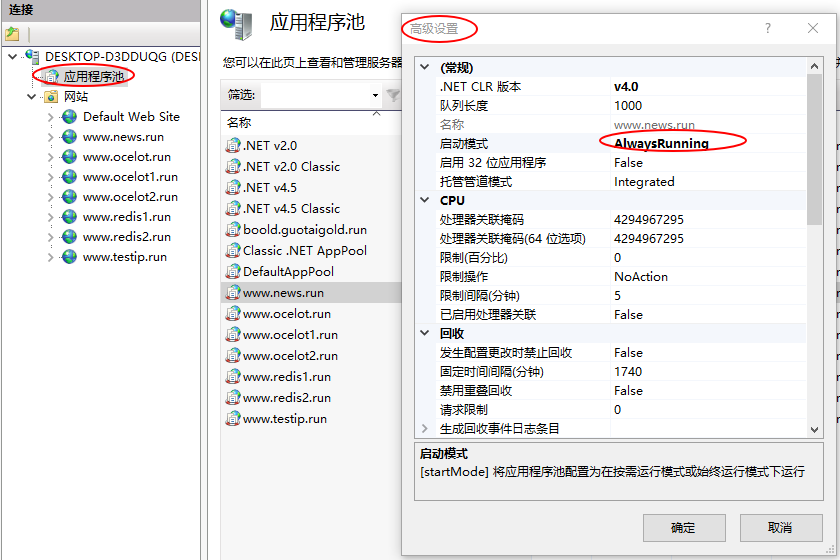
问题现象访问asp.net web项目的时候,第一次访问比较慢,当闲置一段时间后,再次访问还是会非常慢。问题原因这是IIS回收造成的,再次访问的时候会初始化操作,初始化需要耗费时间,所以访问会比较慢,第二次访问的时候不需要初始化操作,因此变快了。解决办法IIS应用初始化会在网站第一次创建后或者对应网
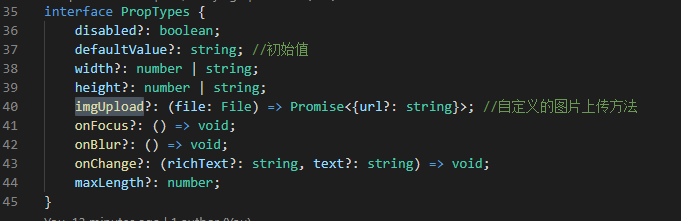
最近项目中需要使用富文本编辑器,参考了运营小姐姐日常使用平台上的编辑器,最后考虑采用百度的UMEditor。因为轻量,功能和配置简单,没有很多定制化的功能,所以没采用UEditor。不过我后续会出一篇文章将UEditor的二次开发。umeditor的引入组件设计首先看一下组件大致的内容:1.组件pr
测试环境:ie8 ff13.0.1 chrome22 可以将分页获取的内容依次填入四个div中,瀑布流的分页可以以多页(比如5页)为单位二次分页,这样可以减少后台算法的复杂度 实现代码如下: waterfall flow body{margin:0px;} #main{width:840
inline onclick代码如下: 实现代码如下: btnOKClick的代码: 实现代码如下: function btnOKClick() { alert("btnOK Clicked"); }现在要在点击按钮以后,移除onclick事件,并为按钮绑定一个新的click事件。在第二次点击时候,
有时候在读取数据库之后,针对同一结果集,在同一个页面上输出的时候可能会碰到多次输出,也就是多次执行mysql_fetch_array(),在第二次执行的时候,如果不加处理,就不会输出任何内容,这种情况下只需要对循环指针进行复位即可。 第一次执行: 实现代码如下: while($row=mysql_f
创建自定义编辑器: 实现代码如下: //引入editor_config.js,editor_api.js,ueditor.css文件,然后在body中创建编辑器实例与父容器 var editorOption = { toolbars:[['FullScreen', 'Source', 'Undo
一、Java中断的现象 首先,看看Thread类里的几个方法: public static boolean interrupted测试当前线程是否已经中断。线程的中断状态 由该方法清除。换句话说,如果连续两次调用该方法,则第二次调用将返回 false(在第一次调用已清除了其中断状态之后,且第二次调用