C#自动获取文件编码txt自动判断文件编码
今天在用c#读取txt文件,乱码了,用默认的编码不行,得用指定的编码才可以.因为每个文件的编码可能都不一样,有没有一种一劳永逸的方法,那肯定是有~自动判断文件的编码.下面就直接上代码了.public static Encoding GetEncoding(string filename){try{r
今天在用c#读取txt文件,乱码了,用默认的编码不行,得用指定的编码才可以.因为每个文件的编码可能都不一样,有没有一种一劳永逸的方法,那肯定是有~自动判断文件的编码.下面就直接上代码了.public static Encoding GetEncoding(string filename){try{r
bat加密脚本(保存为.BAT文件) @echo off cls color 2a :start cls echo ******************************************************************************* echo * * ech
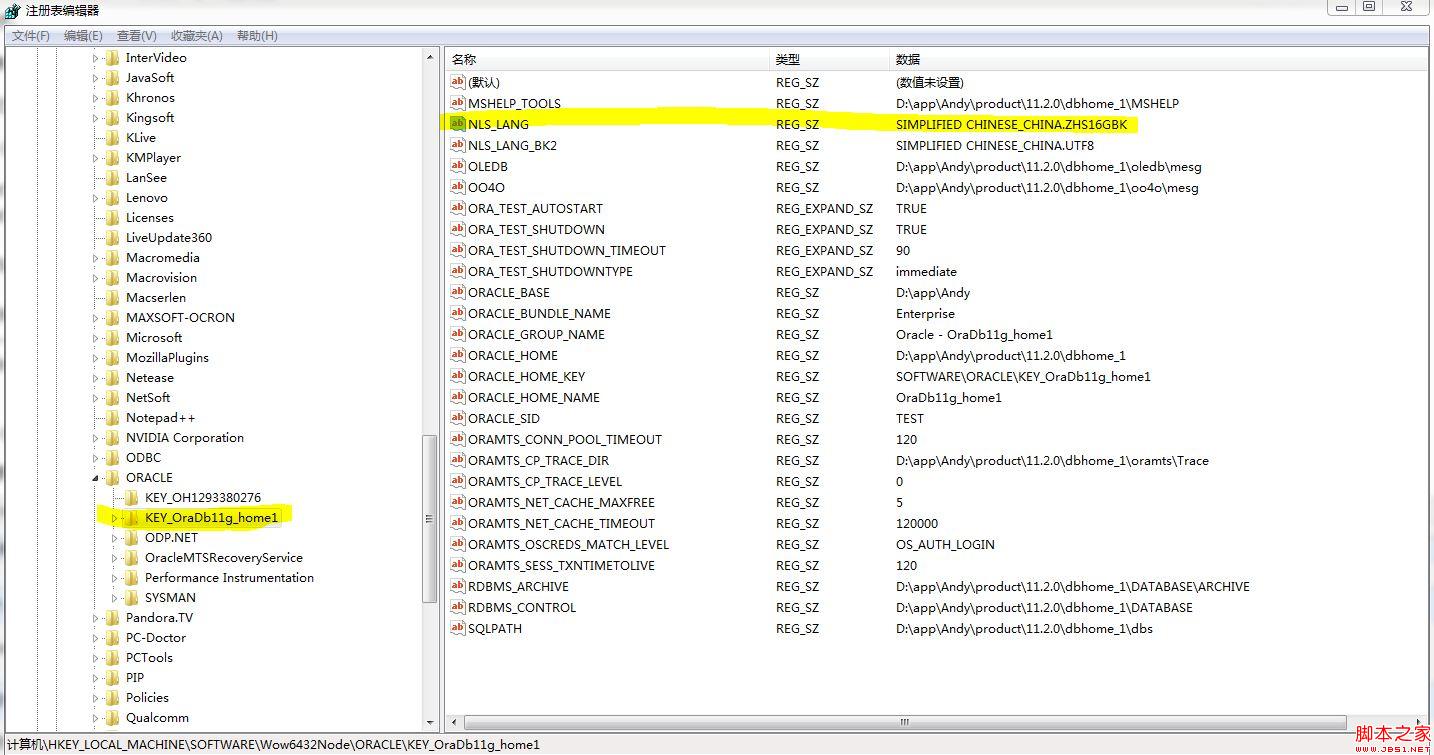
问题描述: 经常有些朋友会遇到,我明明是输入的正确中文,为什么我在另外一台电脑上查询却出现乱码啦?其实这个是数据库在进行字符集转换的时候出现了问题, 下面通过测试来描述具体的情况: 1.环境 Oracle 数据库字符集: Connected to Oracle Database 11g Enterp
mysql链接建立之后,通过如下方式设置编码: 实现代码如下: mysql_query("SET character_set_connection=" . $GLOBALS['charset'] . ",character_set_results=" . $GLOBALS['charset'] .
今天闲的无聊,把以前遗留的问题解决一下,比如让人头痛的Jquery乱码问题。其实这方面文章已经很多了,但全面解决各种问题的很少,今天总结一下,方便自己也方便大家。原因很简单: 其实他的中文乱码就是因为contentType没有指定编码,对于不同Jquery的版本中这个地方有不同的设置,就拿我遇到的,
asp.net中在用ajax格式传递数据到aspx页面时有时会出现乱码,以下为解决方法 js中 : 实现代码如下: XmlHttp.open("POST", "test.aspx", false); XmlHttp.setRequestHeader("Content-Type", "applicat
2013-1-16 10:35:49 org.apache.tomcat.util.http.Parameters processParameters 警告: Parameters: Character decoding failed. Parameter 'id' with value '%u8B
这几天做后台看了一些Ext的知识,在切入工作项目的时候出现了乱码情况,所以就总结了这篇ExtJS中文乱码之GBK格式编码解决办法的文章,作为记录。1、具体情况:在引入:实现代码如下:Ext-学习|测试项目 02. 03. 04. 05.后,写了一个简单的例子:实现代码如下:Ext.onReady(f
当在网站使用伪静态的时候.显示中文出现乱码.不妨在你的伪静态页面中加上[QSA,NU,PT,L]试试 比如将 RewriteRule ^(.*)$ index.php?$1 [L] 改成 RewriteRule ^(.*)$ index.php?$1 [QSA,NU,PT,L] 试试效果. 主要是N
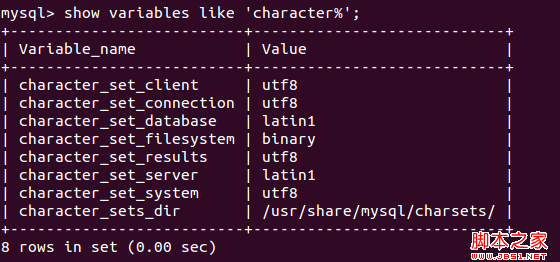
mysql数据库的默认编码并不是utf-8。安装mysql后,启动服务并登陆,使用show variables命令可查看mysql数据库的默认编码:由上图可见database和server的字符集使用了latin1编码方式,不支持中文,即存储中文时会出现乱码。以下是命令行修改为utf-8编码的过程,