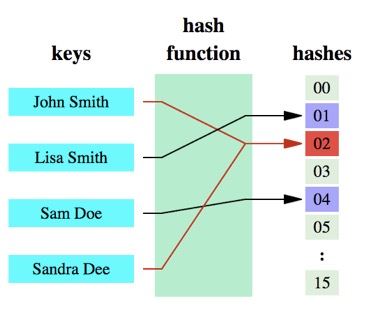
布隆过滤器(bloom filter)及php和redis实现布隆过滤器的方法
引言在介绍布隆过滤器之前我们首先引入几个场景。场景一在一个高并发的计数系统中,如果一个key没有计数,此时我们应该返回0,但是访问的key不存在,相当于每次访问缓存都不起作用了。那么如何避免频繁访问数量为0的key而导致的缓存被击穿?有人说, 将这个key的值置为0存入缓存不就行了吗?确实,这是一个
引言在介绍布隆过滤器之前我们首先引入几个场景。场景一在一个高并发的计数系统中,如果一个key没有计数,此时我们应该返回0,但是访问的key不存在,相当于每次访问缓存都不起作用了。那么如何避免频繁访问数量为0的key而导致的缓存被击穿?有人说, 将这个key的值置为0存入缓存不就行了吗?确实,这是一个
大家在写div+css的时候经常会用到弹出层,由于IE6的bug,所以当使用多个标签重复写弹出层的时候会遇到后面的层压在了弹出层的上面,这种问题在火狐浏览器下可以用z-index来解决,但是在IE6下面是不起作用的,下面的代码给大家提供了一种此类问题的解决办法,原理如下:用Jquery给弹出层的z轴
最近做到iframe的高度自适应这个问题,网上一搜好多解决方案,而总结起来也就那几种,我逐一尝试这些方案,最后发现在我的项目中都不起作用,后来发现自己做的网页是通过file方式访问的,将网页代码放到apache下通过http协议访问,在iframe加载的时候调用如下js方法: 实现代码如下: fun
昨天做完项目后让测试测试了一把,测试说分页查询貌似不起作用,翻到第4页以后,看到的数据结果都是相同的。 当时我就觉得很纳闷,不可能啊,分页组件应该是好的,咋可能有问题呢。带着疑问,我打开了自己的ide,在自己的机器上跑了一把,果然有问题。 有问题就要找问题: 首先把2条查询结果相同的sql打印出来到
标准的DHTML文档中TEXTAREA的MAXLENGTH属性默认情况下不起作用,只有当事件发生时才起作用 如下:http://spiderscript.net/site/spiderscript/examples/ex_textarea_maxlength.asp 但TEXT中有且起作用, 那么在
有一个文本框,id 为 d,用下面的 js 代码,想让其获得焦点。 document.getElementById("d").focus(); 结果代码在 IE 中不起作用,要让 IE 中也获得焦点,得用类似如下的代码: 实现代码如下:document.body.onload = function(
也就有了如下的疑问:include_path是怎么起作用的?如果有多个include_path顺序是怎么样的?什么情况下include_path不起作用?今天, 我就全面的介绍下这个问题, 先从一个例子开始吧.如下的目录结构:root├ 1.php├ 3.php└ subdir├ 2.php└ 3.
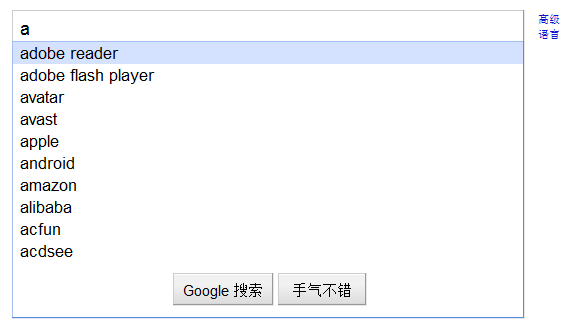
自动补全也成自动完成,最经典的如google的搜索框,输入一个字母后会给用户很多提示选择 查看源码会发现input输入框加上了autocomplete="off",此为了屏蔽浏览器表单默认的记忆功能。淘宝,百度的搜索框也有该属性。autocomplete 属性是非标准的,首先在 IE5 中加入,后
结果点击一个链接直接404 Not Found。悲剧,看来Apache的Rewrite部分有问题了,完全无视掉了.htaccess文件!经过检查Apache的模块,发现Rewrite模块是开启的状态,看来是httpd.conf文件中的配置有点问题了。回想起之前在Ubuntu Server下配置Rew
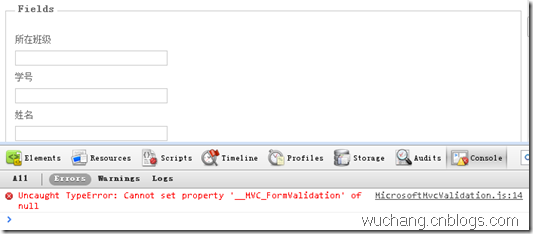
Chrome提示:确定相关JS已经包含在页面中,(用的是MasterPage,二个页面包含的js文件完全相同),排除了js引用路径不正确的问题。页面上生成的mvcClientValidationMetadata也没问题,但客户端验证就是不起作用。将MicrosoftAjax.js替换成Microso