布隆过滤器(bloom filter)及php和redis实现布隆过滤器的方法
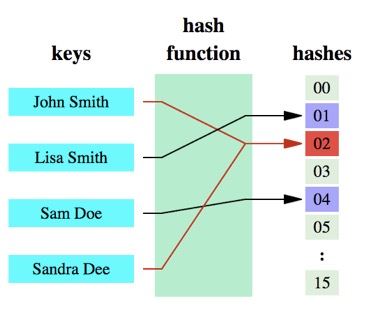
引言在介绍布隆过滤器之前我们首先引入几个场景。场景一在一个高并发的计数系统中,如果一个key没有计数,此时我们应该返回0,但是访问的key不存在,相当于每次访问缓存都不起作用了。那么如何避免频繁访问数量为0的key而导致的缓存被击穿?有人说, 将这个key的值置为0存入缓存不就行了吗?确实,这是一个
引言在介绍布隆过滤器之前我们首先引入几个场景。场景一在一个高并发的计数系统中,如果一个key没有计数,此时我们应该返回0,但是访问的key不存在,相当于每次访问缓存都不起作用了。那么如何避免频繁访问数量为0的key而导致的缓存被击穿?有人说, 将这个key的值置为0存入缓存不就行了吗?确实,这是一个
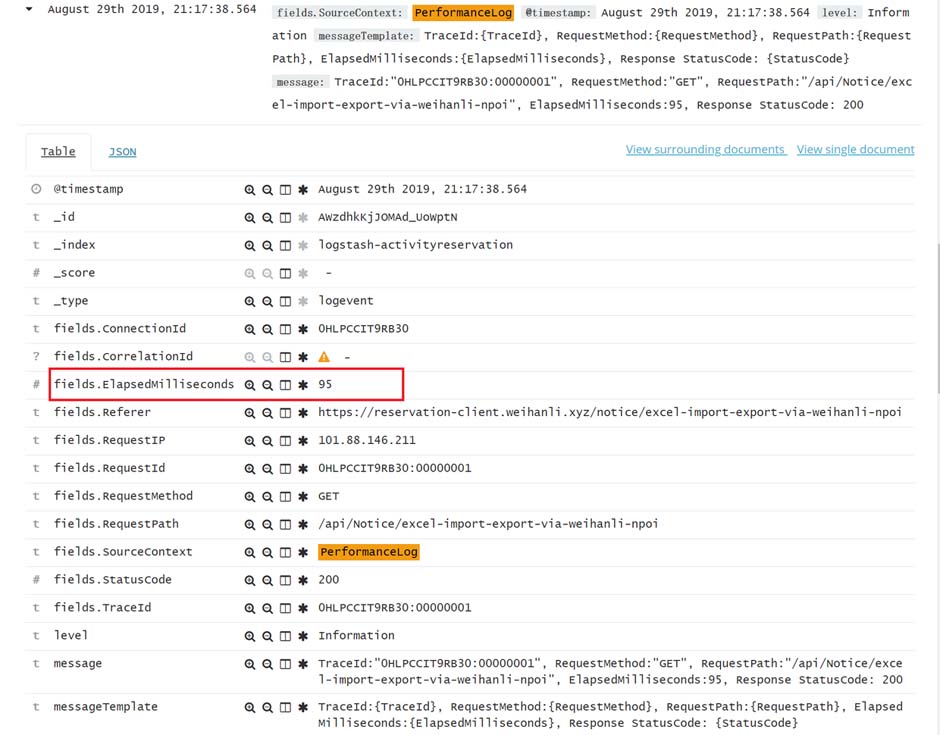
Intro写接口的难免会遇到别人说接口比较慢,到底慢多少,一个接口服务器处理究竟花了多长时间,如果能有具体的数字来记录每个接口耗时多少,别人再说接口慢的时候看一下接口耗时统计,如果几毫秒就处理完了,对不起这锅我不背。中间件实现asp.net core 的运行是一个又一个的中间件来完成的,因此我们只需

我似乎看到了平凡程序员未曾的样子。那些曾经写过代码的大佬们(不能写代码,他们会难过吗?)Bill Gates 盖茨大学用汇编,不间断写了整整一个星期,最后运行bug free。盖茨年轻的时候很厉害,他编写的软件很多。年轻的时候,盖茨很看不起乔布斯,大概的原因就是乔布斯不会编程,不懂技术。
大家在写div+css的时候经常会用到弹出层,由于IE6的bug,所以当使用多个标签重复写弹出层的时候会遇到后面的层压在了弹出层的上面,这种问题在火狐浏览器下可以用z-index来解决,但是在IE6下面是不起作用的,下面的代码给大家提供了一种此类问题的解决办法,原理如下:用Jquery给弹出层的z轴
作为程序猿的你,是否已经喜欢或习惯依赖IDE开发环境呢。作为Java程序猿,我还是蛮深深的依赖Java IDE开发环境滴,比如Eclipse或MyEclipse。有了IDE环境,即使你想不起方法全名,只要知道某个前缀,或哪怕在提示列表中,一一查询,也可以找到自己想找的方法或属性。但是,若是IDE不这
最近做到iframe的高度自适应这个问题,网上一搜好多解决方案,而总结起来也就那几种,我逐一尝试这些方案,最后发现在我的项目中都不起作用,后来发现自己做的网页是通过file方式访问的,将网页代码放到apache下通过http协议访问,在iframe加载的时候调用如下js方法: 实现代码如下: fun
后来在一个不起眼的小站找到一个帖子,某个人的一个建议提醒了我。 我原来的代码是这样写的: 错误代码 实现代码如下: $.ajax({ type: "post", url: "_service.asmx/getDataFromATable", data:" { tablename: temp }",
但是textarea没有这个属性。 asp.net的服务端textbox这个属性也不起效,所以我们只有用js脚本来控制 好,废话不多说,先上代码 javascipt源码: 实现代码如下: function textCounter(field, maxlimit, lines) {//参数说明:fie
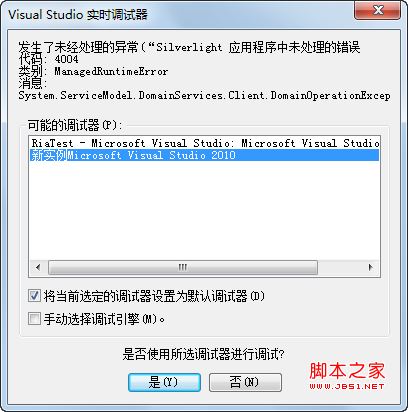
异常出现平常程序遇到错误,开发环境下一般都用调试搞定,生产环境下通过查看日志搞定。但也有搞不定的时候,这是我在Silverlight开发时遇到的的错误:如果启用调试,"对不起,程序已经崩溃,无法附加到进程"。怎么办?提示信息太少,盲目怀疑程序哪里写的不对,只会使问题变得更糟,拖延了解决问题的时间。
昨天做完项目后让测试测试了一把,测试说分页查询貌似不起作用,翻到第4页以后,看到的数据结果都是相同的。 当时我就觉得很纳闷,不可能啊,分页组件应该是好的,咋可能有问题呢。带着疑问,我打开了自己的ide,在自己的机器上跑了一把,果然有问题。 有问题就要找问题: 首先把2条查询结果相同的sql打印出来到