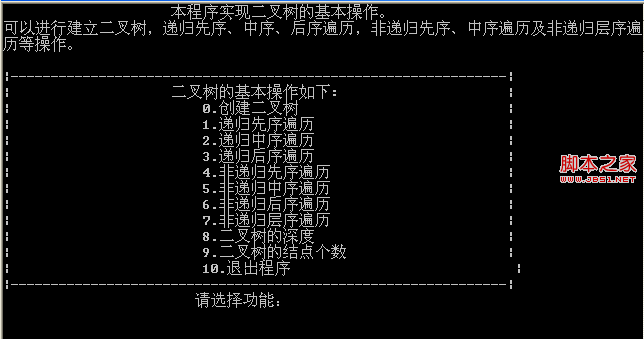
深入遍历二叉树的各种操作详解(非递归遍历)
先使用先序的方法建立一棵二叉树,然后分别使用递归与非递归的方法实现前序、中序、后序遍历二叉树,并使用了两种方法来进行层次遍历二叉树,一种方法就是使用STL中的queue,另外一种方法就是定义了一个数组队列,分别使用了front和rear两个数组的下标来表示入队与出队,还有两个操作就是求二叉树的深度、
先使用先序的方法建立一棵二叉树,然后分别使用递归与非递归的方法实现前序、中序、后序遍历二叉树,并使用了两种方法来进行层次遍历二叉树,一种方法就是使用STL中的queue,另外一种方法就是定义了一个数组队列,分别使用了front和rear两个数组的下标来表示入队与出队,还有两个操作就是求二叉树的深度、
链表概述链表是一种常见的重要的数据结构。它是动态地进行存储分配的一种结构。它可以根据需要开辟内存单元。链表有一个“头指针”变量,以head表示,它存放一个地址。该地址指向一个元素。链表中每一个元素称为“结点”,每个结点都应包括两个部分:一为用户需要用的实际数据,二为下一个结点的地址。因此,head指
float和double型数据分别是单精度和双精度型数,他们的取值分别是3.4E+10的负38次方到3.4E+10的38次方,和1.7E+10的负308次方到1.7E+10的308次方。那么对于float而言,只有6-7位的有效数字,怎么能装下可达3.4*10^(-38)这么大的数呢?同理,15-1
解法1: 我们可以对这个乱序数组按照从大到小先行排序,然后取出前k大,总的时间复杂度为O(n*logn + k)。解法2: 利用选择排序或交互排序,K次选择后即可得到第k大的数。总的时间复杂度为O(n*k)解法3: 利用快速排序的思想,从数组S中随机找出一个元素X,把数组分为两部分Sa和Sb。Sa中
问题:有一个大小为n的数组A[0,1,2,…,n-1],求其中第k大的数。该问题是一个经典的问题,在《算法导论》中被作为单独的一节提出,而且其解决方法很好的利用了分治的思想,将时间复杂度控制在了O(n),这多少出乎我们的意料,此处暂且不表。该问题还可以变形为:有一个大小为 n的数组A[0,1,2,…
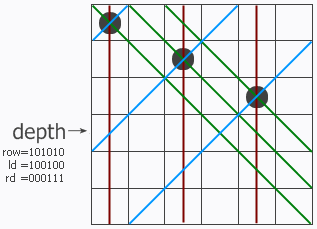
N皇后问题是一个经典的问题,在一个N*N的棋盘上放置N个皇后,每行一个并使其不能互相攻击(同一行、同一列、同一斜线上的皇后都会自动攻击)。一、 求解N皇后问题是算法中回溯法应用的一个经典案例回溯算法也叫试探法,它是一种系统地搜索问题的解的方法。回溯算法的基本思想是:从一条路往前走,能进则进,不能进则
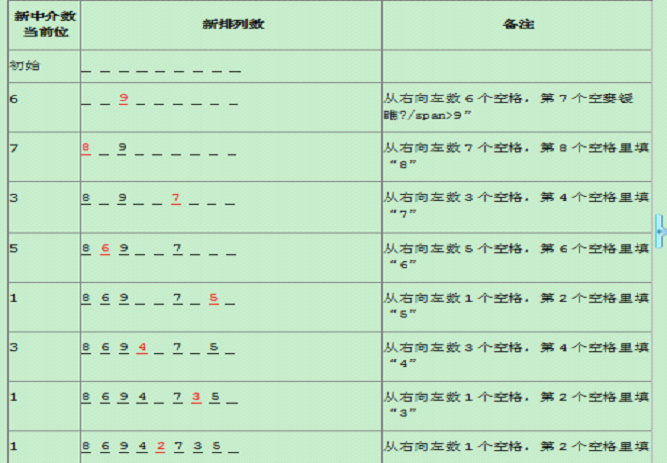
实现代码如下:不论是哪种全排列生成算法,都遵循着“原排列”→“原中介数”→“新中介数”→“新排列”的过程。其中中介数依据算法的不同会的到递增进位制数和递减进位制数。关于排列和中介数的一一对应性的证明我们不做讨论,这里仅仅给出了排列和中介数的详细映射方法。· 递增进位制和递减进位制数所谓递增进位制和递
全排列在很多程序都有应用,是一个很常见的算法,常规的算法是一种递归的算法,这种算法的得到基于以下的分析思路。给定一个具有n个元素的集合(n>=1),要求输出这个集合中元素的所有可能的排列。一、递归实现例如,如果集合是{a,b,c},那么这个集合中元素的所有排列是{(a,b,c),(a,c,b)
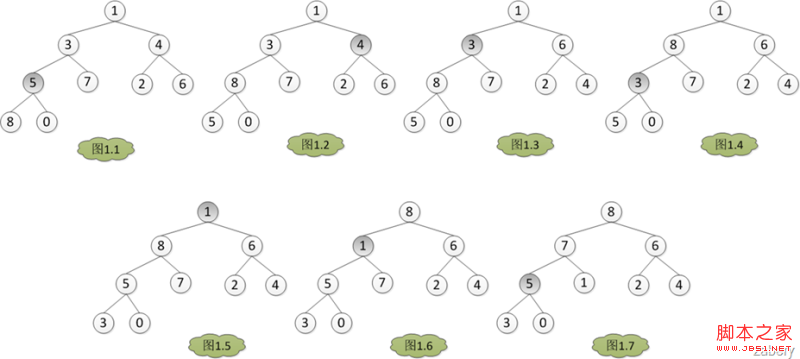
记得在学习数据结构的时候一味的想用代码实现算法,重视的是写出来的代码有一个正确的输入,然后有一个正确的输出,那么就很满足了。从网上看了许多的代码,看了之后貌似懂了,自己写完之后也正确了,但是不久之后就忘了,因为大脑在回忆的时候,只依稀记得代码中的部分,那么的模糊,根本不能再次写出正确的代码,也许在第
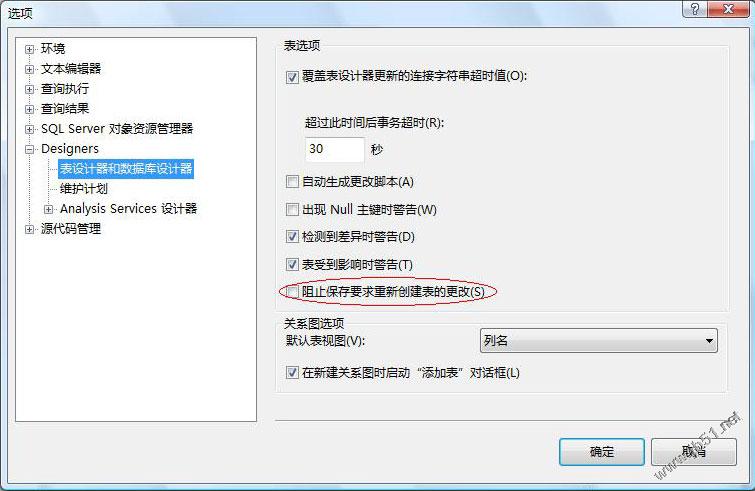
启动SQL Server 2008 Management Studio工具菜单----选项----Designers(设计器)----阻止保存要求重新创建表的更改取消勾选即可。 工具菜单----选项----Designers(设计器)----阻止保存要求重新创建表的更改 取消勾选