SQL Server 高性能写入的一些经验总结
1.1.1 摘要 在开发过程中,我们不时会遇到系统性能瓶颈问题,而引起这一问题原因可以很多,有可能是代码不够高效、有可能是硬件或网络问题,也有可能是数据库设计的问题。本篇博文将针对一些常用的数据库性能调休方法进行介绍,而且,为了编写高效的SQL代码,我们需要掌握一些基本代码优化的技巧,所以,我们将从
1.1.1 摘要 在开发过程中,我们不时会遇到系统性能瓶颈问题,而引起这一问题原因可以很多,有可能是代码不够高效、有可能是硬件或网络问题,也有可能是数据库设计的问题。本篇博文将针对一些常用的数据库性能调休方法进行介绍,而且,为了编写高效的SQL代码,我们需要掌握一些基本代码优化的技巧,所以,我们将从

自动更新统计信息的基本算法是: · 如果表格是在 tempdb 数据库表的基数是小于 6,自动更新到表的每个六个修改。 · 如果表的基数是大于 6,但小于或等于 500,更新状态每 500 的修改。 · 如果基数大于 500,表为更新统计信息时(500 + 20%的表)发生了更改。 · 表变量为基数
可能许多同学对SQL Server的备份和还原有一些了解,也可能经常使用备份和还原功能,我相信除DBA之外我们大部分开发员队伍对备份和还原只使用最基础的功能,对它也只有一个大概的认识,如果对它有更深入的认识,了解它更全面的功能岂不是更好,到用时会得心应手。因为经常有中小型客户公司管理人员对数据库不了
1. 排名函数与PARTITION BY 实现代码如下: --所有数据 SELECT * FROM dbo.student AS a INNER JOIN dbo.ScoreTB AS b ON a.Id = b.stuid WHERE scorename = '语文' --------------
1. TVP, 表变量,临时表,CTE 的区别 TVP和临时表都是可以索引的,总是存在tempdb中,会增加系统数据库开销,而表变量和CTE只有在内存溢出时才会被写入tempdb中。对于数据量大,并且反复使用,反复进行查询关联的,建议使用临时表或TVP,数据量小,使用表变量或CTE比较合适 2. s
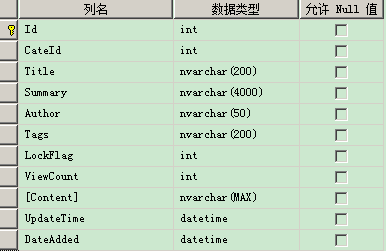
其中 offset and fetch 最重要的新特性是 用来 分页,既然要分析 分页,就肯定要和之前的分页方式来比较了,特别是 Row_Number() 了,在比较过程中,发现了蛮多,不过最重要的,通过比较本质,得出了优劣,也和大家一起分享下。 准备工作,建立测试表:Article_Detail,
一. 建库,建表,加约束. 1.1建库 实现代码如下: use master go if exists (select * from sysdatabases where name='MyDatabase')—判断master数据库sysdatagbases表中是否存在将要创建的数据库名 drop
在本文中,我将说明如何用SQL Server的工具来优化数据库索引的使用,本文还涉及到有关索引的一般性知识。 关于索引的常识 影响到数据库性能的最大因素就是索引。由于该问题的复杂性,我只可能简单的谈谈这个问题,不过关于这方面的问题,目前有好几本不错的书籍可供你参阅。我在这里只讨论

当我们创建一个数据库的时候,例如以缺省的方式CREATE DATABASE TESTDB,SQLServer自动帮我们创建好如下两个数据库文件。 这两个数据文件是实实在在的操作系统文件,其中一个是叫行数据文件,用来存储数据库的各种对象,另外一个是日志文件,从来记录数据变化的过程。 从逻辑角度而言
SQL Server会把经常使用到的数据缓存在内存里(就是数据页缓存),用以提高数据访问速度。因为磁盘访问速度远远低于内存,所以减少磁盘访问量同样是数据库优化的重要方面。 当数据页缓存区出现内存不足,则会出现查询慢,磁盘忙等等问题。 分析方法:主要是用到性能计数器。 查看如下性能计数器: 1. SQ