
Python模块学习 re 正则表达式
re.match re.match 尝试从字符串的开始匹配一个模式,如:下面的例子匹配第一个单词。 实现代码如下: import re text = "JGood is a handsome boy, he is cool, clever, and so on..." m = re.match(
re.match re.match 尝试从字符串的开始匹配一个模式,如:下面的例子匹配第一个单词。 实现代码如下: import re text = "JGood is a handsome boy, he is cool, clever, and so on..." m = re.match(
首先,运行 Python 解释器,导入 re 模块并编译一个 RE:#!python Python 2.2.2 (#1, Feb 10 2003, 12:57:01) >>> import re >>> p = re.compile('[a-z]+') >&
以下的文章主要是以介绍python随机数生成的代码来介绍Python随机数生成在实际操作过程中的具体应用,如果你对其的相关内容感兴趣的话,你就可以点击以下的文章。希望你会对它有所收获。 Python中的random模块用于生成随机数。下面介绍一下random模块中最常用的几个函数。 实现代码如下:
实现代码如下: import random print 'N must >K else error' n=int(raw_input("n=")) k=int(raw_input("k=")) result=[] x=range(n) for i in range(k): t=random.r
Python是一种面向对象的解释性的计算机程序设计语言,也是一种功能强大而完善的通用型语言,已经具有十多年的发展历史,成熟且稳定。Python 具有脚本语言中最丰富和强大的类库,足以支持绝大多数日常应用。它具有简单、易学、免费、开源、可移植性、解释性、面向对象、可扩展性、可嵌入性以及丰富的库等特性,
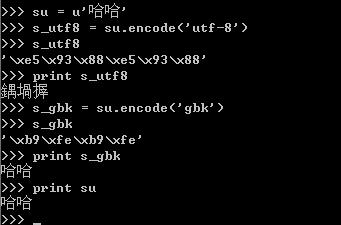
在本文中,以'哈'来解释作示例解释所有的问题,“哈”的各种编码如下: 1. UNICODE (UTF8-16),C854; 2. UTF-8,E59388; 3. GBK,B9FE。 一、python中的str和unicode 一直以来,python中的中文编码就是一个极为头大的问题,经常抛出编码转
概括、从python1.6开始就可以处理unicode字符了。 一、几种常见的编码格式。 1.1、ascii,用1个字节表示。 1.2、UTF-8,用1个至三个字节表示,表示ascii码时只占用1个字节,ascii编码是UTF-8的子集。 1.3、UTF-16,用2个字节表示,在python中,un
word中对于英文单词的统计也很好,大家不妨试试。如果没有安装word,而且你也是程序员的话,那么可以使用我的这段代码。通过测试,word的统计结果是18674,软件的统计结果是18349,相差不到2%,可以作为一个参考。 代码如下: 实现代码如下: # -*- coding: utf-8 -*
但是,当一本书学过之后,对一般的技术和函数都有了印象,突然想要查找某个函数的实例代码时,却感到很困难,因为一本书的源代码目录很长,往往有几十甚至上百个源代码文件,想要找到自己想要的函数实例谈何容易? 所以这里就是要将所有源代码按照目录和文件名作为标签,全部合并到一处,这样便于快速的搜索。查找,不
列表解析 在需要改变列表而不是需要新建某列表时,可以使用列表解析。列表解析表达式为: [expr for iter_var in iterable] [expr for iter_var in iterable if cond_expr] 第一种语法:首先迭代iterable里所有内容,每一次迭代,