
mysql导入导出数据中文乱码解决方法小结
linux系统中 linux默认的是utf8编码,而windows是gbk编码,所以会出现上面的乱码问题。 解决mysql导入导出数据乱码问题 首先要做的是要确定你导出数据的编码格式,使用mysqldump的时候需要加上--default-character-set=utf8, 例如下面的代码: 实
linux系统中 linux默认的是utf8编码,而windows是gbk编码,所以会出现上面的乱码问题。 解决mysql导入导出数据乱码问题 首先要做的是要确定你导出数据的编码格式,使用mysqldump的时候需要加上--default-character-set=utf8, 例如下面的代码: 实
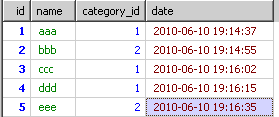
--按某一字段分组取最大(小)值所在行的数据 实现代码如下: /* 数据如下: name val memo a 2 a2(a的第二个值) a 1 a1--a的第一个值 a 3 a3:a的第三个值 b 1 b1--b的第一个值 b 3 b3:b的第三个值 b 2 b2b2b2b2 b 4 b4b4 b
以前一直都认为有两个字节来记录长度(长度小也可以用一个字节记录),所以这个问题当时觉得就挺无聊的不过后来群里有人给了解释,突然才发现原来事情不是这么简单 MYSQL COMPACT格式,每条记录有一个字节来表示NULL字段分布,如果表中有字段允许为空,则最大只能定到65532,如果没有字段允许为空,
安装完MySQL以后会自动创建一个root用户和一个匿名用户,对于root大家都非常注意,而这个匿名用户很多人都会忽略,大概是因为匿名用户默认设定为只能在本地使用的缘故吧。但如果MySQL要作为数据库提供给Web服务器使用的话,忽略这个匿名用户的代价可能相当惨重。因为在默认设置下,这个匿名用户在lo
他们将讨论返回数据的语句,例如INSERT以及不返回数据的语句,例如UPDATE和DELETE。然后,他们将编写从数据库检索数据的简单程序执行SQL语句 现在,我们已经有了一个连接,并且知道如何处理错误,是时候讨论使用我们的数据库来作一些实际工作了。执行所有类型的SQL的主关键字是mysql_que
首先停止mysql服务: 实现代码如下: root@webserver:/home/webmaster# service mysql stop接着采用忽略密码认证模式重新创建一个mysql服务: 实现代码如下: root@webserver:/home/webmaster# mysqld --use
SQL模式匹配允许你使用“_”匹配任何单个字符,而“%”匹配任意数目字符(包括零字符)。在 MySQL中,SQL的模式默认是忽略大小写的。下面给出一些例子。注意使用SQL模式时,不能使用=或!=;而应使用LIKE或NOT LIKE比较操作符。要想找出以“b”开头的名字: mysql> SELE
连接与断开服务器连接服务器通常需要提供一个MySQL用户名并且很可能需要一个 密码。如果服务器运行在登录服务器之外的其它机器上,还需要指定主机名: shell> mysql -h host -u user -pEnter password: ********host代表MySQL服务器运行的主
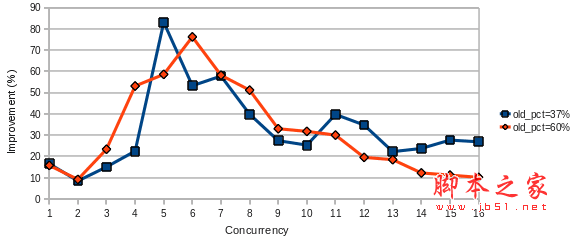
前言:最近Oracle MySQL在其官方Blog上贴出了 5.6中一些变量默认值的修改。其中innodb_old_blocks_time 的默认值从0替换成了1000(即1s)关于该参数的作用摘录如下:how long in milliseconds (ms) a block inserted i
先建立2个测试表,在id列上创建unique约束。 mysql> create table test1(id int,name varchar(5),type int,primary key(id)); Query OK, 0 rows affected (0.01 sec) mysql>