
SQL Server自动更新统计信息的基本算法
自动更新统计信息的基本算法是: · 如果表格是在 tempdb 数据库表的基数是小于 6,自动更新到表的每个六个修改。 · 如果表的基数是大于 6,但小于或等于 500,更新状态每 500 的修改。 · 如果基数大于 500,表为更新统计信息时(500 + 20%的表)发生了更改。 · 表变量为基数
自动更新统计信息的基本算法是: · 如果表格是在 tempdb 数据库表的基数是小于 6,自动更新到表的每个六个修改。 · 如果表的基数是大于 6,但小于或等于 500,更新状态每 500 的修改。 · 如果基数大于 500,表为更新统计信息时(500 + 20%的表)发生了更改。 · 表变量为基数

下面把代码写出来,希望大家批评指正. 首先domain对象.在这里使用的注解的方式,都是比较新的版本. User.java 实现代码如下: package com.bao.sample.s3h4.domain; import javax.persistence.Column; import java
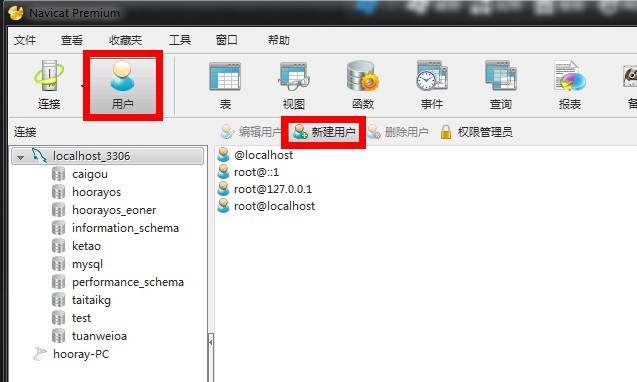
一、如何新建独立帐号并设置权限 这里我使用Navicat作为我的数据库管理工具,打开Navicat。选择“用户”--“新建用户”输入用户名、主机、密码,需要注意的是,主机那不是写“localhost”,而是写“%”然后可以设置“服务器权限”和指定数据库的权限,最后保存退出即可二、远程连接慢 慢是一个
例如,如果列a被定义为unique,并且值为1,则下列语句有同样的效果,也就是说一旦出入的记录中存在a=1的情况,直接更新c = c + 1,而不执行c = 3的操作。 实现代码如下: insert into table(a, b, c) values (1, 2, 3) on duplicate
在window下,启动、停止mysql服务 启动mysql数据库 net start mysql 停止mysql数据库 net stop mysql 重新启动mysql数据库 net restart mysql 命令行形式,mysql基本命令的使用 1、命令的取消 \c 2、退出mysql窗口 ex
可能许多同学对SQL Server的备份和还原有一些了解,也可能经常使用备份和还原功能,我相信除DBA之外我们大部分开发员队伍对备份和还原只使用最基础的功能,对它也只有一个大概的认识,如果对它有更深入的认识,了解它更全面的功能岂不是更好,到用时会得心应手。因为经常有中小型客户公司管理人员对数据库不了
1. 排名函数与PARTITION BY 实现代码如下: --所有数据 SELECT * FROM dbo.student AS a INNER JOIN dbo.ScoreTB AS b ON a.Id = b.stuid WHERE scorename = '语文' --------------
1. TVP, 表变量,临时表,CTE 的区别 TVP和临时表都是可以索引的,总是存在tempdb中,会增加系统数据库开销,而表变量和CTE只有在内存溢出时才会被写入tempdb中。对于数据量大,并且反复使用,反复进行查询关联的,建议使用临时表或TVP,数据量小,使用表变量或CTE比较合适 2. s
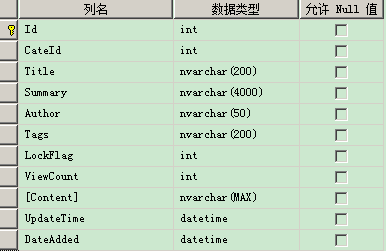
其中 offset and fetch 最重要的新特性是 用来 分页,既然要分析 分页,就肯定要和之前的分页方式来比较了,特别是 Row_Number() 了,在比较过程中,发现了蛮多,不过最重要的,通过比较本质,得出了优劣,也和大家一起分享下。 准备工作,建立测试表:Article_Detail,
一. 建库,建表,加约束. 1.1建库 实现代码如下: use master go if exists (select * from sysdatabases where name='MyDatabase')—判断master数据库sysdatagbases表中是否存在将要创建的数据库名 drop