nodejs的require模块(文件模块/核心模块)及路径介绍
在nodejs中,模块大概可以分为核心模块和文件模块。 核心模块是被编译成二进制代码,引用的时候只需require表示符即可,如(require('net'))。 文件模块,则是指js文件、json文件或者是.node文件。在引用文件模块的时候后要加上文件的路径:/.../.../xxx.js表示绝
在nodejs中,模块大概可以分为核心模块和文件模块。 核心模块是被编译成二进制代码,引用的时候只需require表示符即可,如(require('net'))。 文件模块,则是指js文件、json文件或者是.node文件。在引用文件模块的时候后要加上文件的路径:/.../.../xxx.js表示绝
实现代码如下: //数据 DataTable dtObject = dt; //保留列 string[] saveColumns = new string[5]; saveColumns[0] = "X";//保留列1 saveColumns[1] = "XX";//保留列2 saveColumns
var url = "http://www.xxx.com/index.aspx?classid=9 要获取尾巴参数 定义变量 实现代码如下: function parse_url(_url){ //定义函数 var pattern = /(\w+)=(\w+)/ig;//定义正则表达式 var p
如果是导入有中文的数据,我的mysql 设置的utf8 字符集,所以你要导入的xxx.txt 文件也要保存utf-8的字符集,命令 load data infile "d:/Websites/Sxxxx/test1.txt" ignore into table `names` fields term
今天在犀牛书上发现了一个有用的函数 urlArgs(提取URL的搜索字符串中的参数)。我们经常会看到有的页面链接地址后面会跟有参数,比如 http://www.xxx.com/?username=yyy var query = location.search.substring(1); var pa
公司的域环境内,要求获取客户端的电脑名称,其实程序原开始,只是要求 获取客户端IP地址 后来演变成要求显示客户端的电脑名称。作为开发者,只有不停地实现客户的要求。 其实既然IP获取到了,那可以轻易以IP来获取电脑名称: 实现代码如下: System.Net.Dns.GetHostEntry("xxx
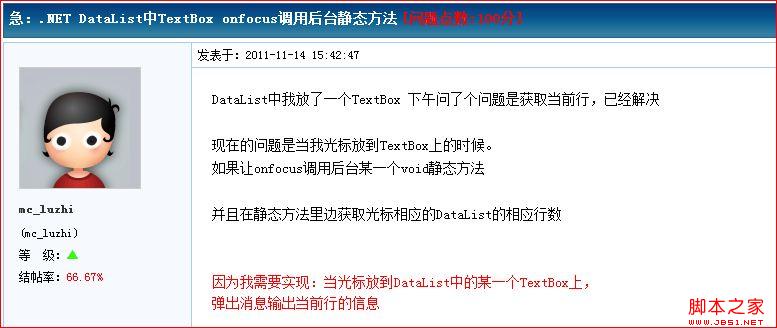
昨天在某一论坛上看到的。Insus.NET尝试做了一下,算是练习了。Insus.NET的测试演示:xxx.aspx: 实现代码如下: 物料编码 xxx.aspx.cs:实现代码如下: protected void dlItemGeneral_ItemDataBound(o
Python版本 实现了比之前的xxftp更多更完善的功能 1、继续支持多用户 2、继续支持虚拟目录 3、增加支持用户根目录以及映射虚拟目录的权限设置 4、增加支持限制用户根目录或者虚拟目录的空间大小 xxftp的特点 1、开源、跨平台 2、简单、易用 3、不需要数据库 4、可扩展性超强 5、你可以
实现代码如下: 'http://www.xx.com/images/banner-header.gif', //盗链返回的地址 'url_1' => 'http://www.xx.net/file', 'url_2' => 'http://www.xx.net/file1', ); $
安装环境 centos 5.4 mysql 5.1.xx 采用rpm直接安装 xtrabackup 1.2.22 采用rpm直接安装 1. Master:/etc/my.cnf [mysqld] server-id = 1 log-bin innodb_flush_log_at_trx_commit