探讨select in 在postgresql的效率问题
在知乎上看到这样一个问题:MySQL 查询 select * from table where id in (几百或几千个 id) 如何提高效率?修改电商网站,一个商品属性表,几十万条记录,80M,索引只有主键id,做这样的查询如何提高效率?select * from table where id
在知乎上看到这样一个问题:MySQL 查询 select * from table where id in (几百或几千个 id) 如何提高效率?修改电商网站,一个商品属性表,几十万条记录,80M,索引只有主键id,做这样的查询如何提高效率?select * from table where id
一、简介序列对象(也叫序列生成器)就是用CREATE SEQUENCE 创建的特殊的单行表。一个序列对象通常用于为行或者表生成唯一的标识符。二、创建序列方法一:直接在表中指定字段类型为serial 类型david=# create table tbl_xulie (david(# id serial
postgresql版本:psql (9.3.4)1、增加一列实现代码如下:ALTER TABLE table_name ADD column_name datatype;2、删除一列实现代码如下:ALTER TABLE table_name DROPcolumn_name;3、更改列的数据类型实现
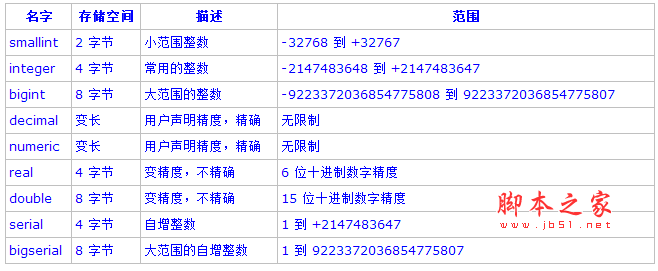
一、数值类型:下面是PostgreSQL所支持的数值类型的列表和简单说明:1. 整数类型:类型smallint、integer和bigint存储各种范围的全部是数字的数,也就是没有小数部分的数字。试图存储超出范围以外的数值将导致一个错误。常用的类型是integer,因为它提供了在范围、存储空间和性能
一、恢复磁盘空间:在PostgreSQL中,使用delete和update语句删除或更新的数据行并没有被实际删除,而只是在旧版本数据行的物理地址上将该行的状态置为已删除或已过期。因此当数据表中的数据变化极为频繁时,那么在一段时间之后该表所占用的空间将会变得很大,然而数据量却可能变化不大。要解决该问题
一、pg_class:该系统表记录了数据表、索引(仍然需要参阅pg_index)、序列、视图、复合类型和一些特殊关系类型的元数据。注意:不是所有字段对所有对象类型都有意义。 名字类型引用描述relnamename 数据类型名字。relnamespaceoidpg_namespace.oid包含这个对
一、pg_tables:该视图提供了对有关数据库中每个表的有用信息地访问。名字类型引用描述schemanamenamepg_namespace.nspname包含表的模式名字。tablenamenamepg_class.relname表的名字。tableownernamepg_authid.roln
一、概述:PL/pgSQL函数在第一次被调用时,其函数内的源代码(文本)将被解析为二进制指令树,但是函数内的表达式和SQL命令只有在首次用到它们的时候,PL/pgSQL解释器才会为其创建一个准备好的执行规划,随后对该表达式或SQL命令的访问都将使用该规划。如果在一个条件语句中,有部分SQL命令或表达
一、索引的类型:PostgreSQL提供了多 种索引类型:B-Tree、Hash、GiST和GIN,由于它们使用了不同的算法,因此每种索引类型都有其适合的查询类型,缺省时,CREATE INDEX命令将创建B-Tree索引。1. B-Tree: 实现代码如下:CREATE TABLE test1
六、模式匹配:PostgreSQL中提供了三种实现模式匹配的方法:SQL LIKE操作符,更近一些的SIMILAR TO操作符,和POSIX-风格正则表达式。1. LIKE: 实现代码如下:string LIKE pattern [ ESCAPE escape-character ]string N