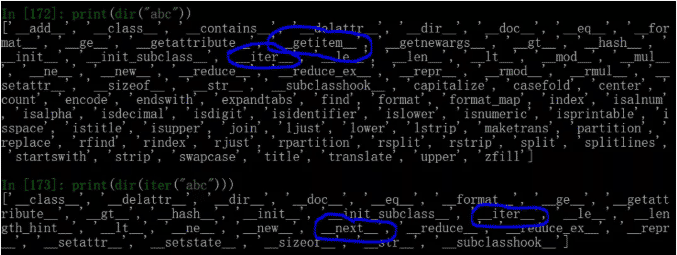
Python进阶之迭代器与迭代器切片教程
在前两篇关于 Python 切片的文章中,我们学习了切片的基础用法、高级用法、使用误区,以及自定义对象如何实现切片用法(相关链接见文末)。本文是切片系列的第三篇,主要内容是迭代器切片。迭代器是 Python 中独特的一种高级特性,而切片也是一种高级特性,两者相结合,会产生什么样的结果呢?1、迭代与迭
在前两篇关于 Python 切片的文章中,我们学习了切片的基础用法、高级用法、使用误区,以及自定义对象如何实现切片用法(相关链接见文末)。本文是切片系列的第三篇,主要内容是迭代器切片。迭代器是 Python 中独特的一种高级特性,而切片也是一种高级特性,两者相结合,会产生什么样的结果呢?1、迭代与迭

1. this.Session["username"] = nullHttpSessionState 内部使用 NameObjectCollection 类型的集合对象来存储用户数据。因此使用 this.Session["username"] = null 仅仅是将该元素的值设为 null 而已,并
误区 #1:在服务器故障转移后,正在运行的事务继续执行 这当然是错误的! 每次故障转移都伴随着某种形式的恢复。但是如果当正在执行的事务没有Commit时,由于服务器或实例崩溃导致连接断开,SQL Server可没有办法在故障转移后的服务器重新建立事务的上下文并继续执行事务-无论你使用的故障转移方式是
误区 #2: DBCC CHECKDB会引起阻塞,因为这个命令默认会加锁这是错误的!在SQL Server 7.0以及之前的版本中,DBCC CHECKDB命令的本质是C语言实现的一个不断嵌套循环的代码并对表加表锁(循环嵌套算法时间复杂度是嵌套次数的N次方,作为程序员的你懂得),这种方式并不和谐,并
本系列文章是我在sqlskill.com的PAUL的博客看到的,很多误区都比较具有典型性和代表性,原文来自T-SQL Tuesday #11: Misconceptions about.... EVERYTHING!!,经过我们团队的翻译和整理发布在AgileSharp和博客园上。希望对大家有所帮助
误区 #4: DDL触发器(SQL Server 2005之后被引入)就是INSTEAD OF触发器这是错误的DDL触发器的实现原理其实就是一个AFTER触发器。这个意思是先发生DDL操作,然后触发器再捕捉操作(当然如果你在触发器内写了Rollback,则也可能回滚)。存在Rollback也意味着这
这样还能减少CPU缓存命中失效的问题(点击这个链接来查看CPU的缓存是如何工作的以及MESI协议)。下面让我们来揭穿三个有关NULL位图的普遍误区。 误区 #6a:NULL位图并不是任何时候都会用到 正确 就算表中不存在允许NULL的列,NULL位图对于数据行来说会一直存在(数据行指的是堆或是聚集索
误区 #7:一个数据库可以存在多个镜像 错误 这个误区就有点老生常谈了。每一个主体服务器只允许一个镜像服务器。如果你希望存在多个主体服务器的副本,那么请使用事务日志传送,事务日志传送允许针对每一个主体存在多个辅助实例。 使用事务日志传送的一个优点是允许其中一个或多个辅助服务器存在延迟还原备份。这也是
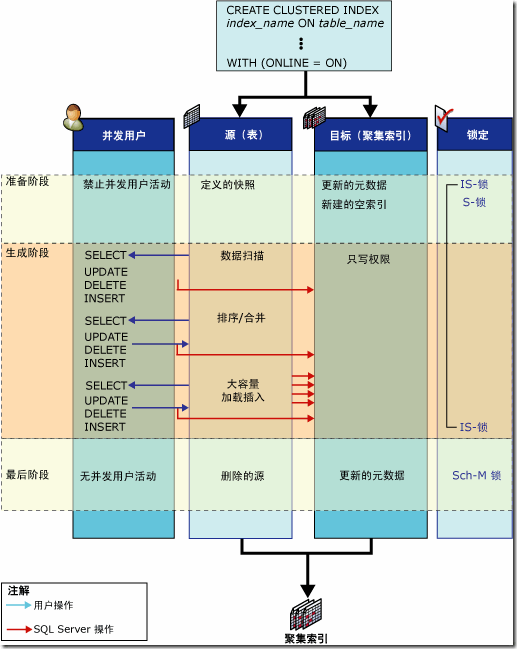
误区 #8: 在线索引操作不会使得相关的索引加锁错误!在线索引操作并不是想象的那么美好。在线索引操作会在操作开始时和操作结束时对资源上短暂的锁。这有可能导致严重的阻塞问题。在线索引操作开始时,会在被整理的资源上加一个共享的表锁,这个表锁在会在新的索引创建时、老索引进行版本扫描时一直持续。但问题是,这
误区 #9: 数据库文件收缩不会影响性能错误!收缩数据库文件唯一不影响性能的情况是文件末尾有剩余空间的情况下,收缩文件指定了TruncateOnly选项。收缩文件的过程非常影响性能,这个过程需要移动大量数据从而造成大量IO,这个过程会被记录到日志从而造成日志暴涨,相应的,还会占去大量的CPU资源。不