对字符串进行HTML编码和解码的JavaScript函数
编码函数: 实现代码如下: function HtmlEncode(str) { var t = document.createElement("div"); t.textContent ? t.textContent = str : t.innerText = str; return t.inne
编码函数: 实现代码如下: function HtmlEncode(str) { var t = document.createElement("div"); t.textContent ? t.textContent = str : t.innerText = str; return t.inne
>>> teststr = '我的eclipse不能正确的解码gbk码!' >>> teststr '\xe6\x88\x91\xe7\x9a\x84eclipse\xe4\xb8\x8d\xe8\x83\xbd\xe6\xad\xa3\xe7\xa1\xae\x
需求 在js中将中文用gb2312编码。如,“我”编码后应该是“%CE%D2”。 分析 大家知道,encodeURI和encodeURIComponent会用utf-8编码,如“我”编码后是“%E6%88%91”。据实验,似乎没有参数指定编码的地方。只有另寻他法。 大致分析有如下几种解决方案: 1.
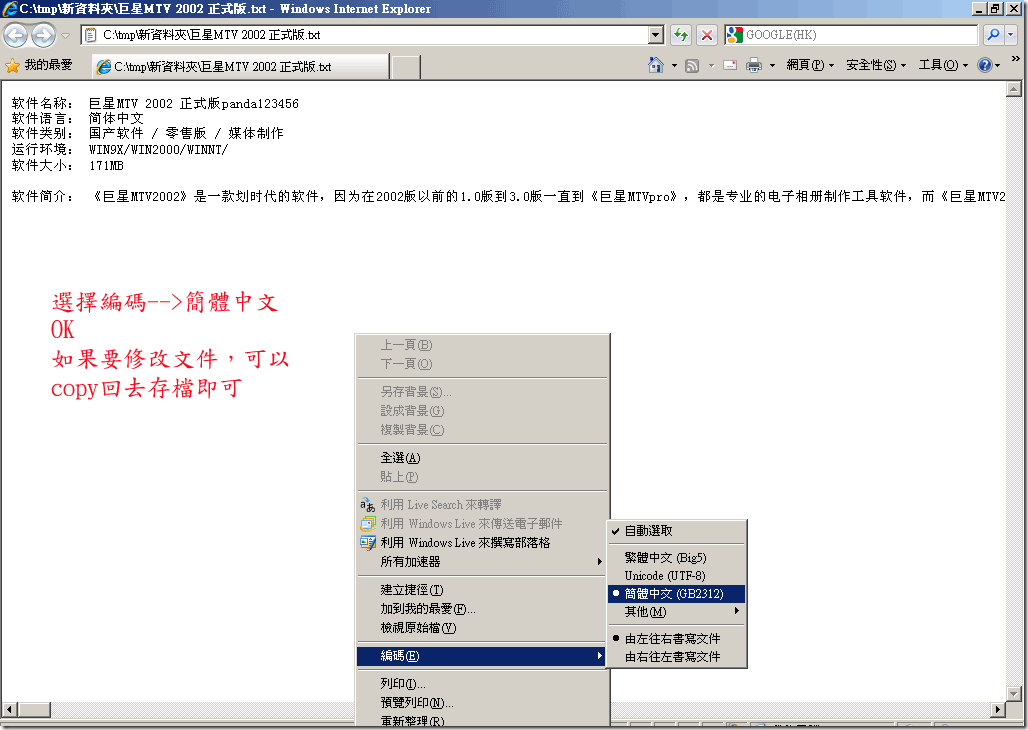
简单的请求,简单的响应,但是乱码产生了Why?乱码之所以产生,原因很简单,无非就是编码表用错了,如传的是big5字符,接收却使用utf-8,或utf-8编码,却用GB2312解码。 好吧,先确认一下是否请求过程中产生的乱码 那我发过去的是乱码吗? 打开C:/tmp/下的test.txt 这是什么编码
分析可以知道,此木马经过了base64进行了编码,然后进行压缩。虽然做了相关的保密措施,可是php代码要执行,其最终要生成php源代码,所以写出如下php程序对其进行解码,解压缩,写入文件。解码解压缩代码如下:实现代码如下: 然后在php的环境下进行运行,会得到php明文文件如下: 实现代码如下:e
实现代码如下:String.prototype.HTMLEncode = function() { var temp = document.createElement ("div"); (temp.textContent != null) ? (temp.textContent = this) :

是因为XMLHttp在处理返回的responstText的时候把responstBody按UTF-8编码进行解码的,如果服务器端送出的数据流的确是UTF-8编码,那么中文字就会正确显示,但如果是GBK或是其他编码则会出现上述情况。 解决的办法是在服务器端返回的数据流中加上一个header,指明送出的
在非英文字符集的页面上,如果使用Ajax方式进行数据交互的话,就必须要注意保证前后端数据的统一编码,否则,很容易就出现乱码! 在后端是ASP程序的情况下,保持前端Javascript和Asp之间传值的统一编码可以使用以下函数进行处理: 编码:escape(string) 解码:unescape(st
base64+gzinflate压缩编码(加密)过的文件通常是以 100){ // 去除PHP文件注释和空白,减少文件大小 $contents = php_strip_whitespace($filename); // 去除PHP头部和尾部标识 $headerPos = strpos($conten
虽然escape()、encodeURI()、encodeURIComponent()三种方法都能对一些影响URL完整性的特殊 字符进行过滤。但后两者是将字符串转换为UTF-8的方式来传输,解决了页面编码不一至导致的乱码问 题。例如:发送页与接受页的编码格式(Charset)不一致(假设发送页面是G